

목차
8 텍스트 분류
8.1 텍스트 분류 정의
8.2 RNN을 사용한 텍스트 분류
8.1 텍스트 분류 정의
텍스트 분류란?
텍스트 데이터를 입력으로 받아 지정된 카테고리에 대한 수치를 출력하는 것
예) 카테고리 분류, 주제 분류, 감성 분석

텍스트 분류란? (확률 관점에서)
문장이 주어질 때(x), 문장이 속할 카테고리의(y) 확률 분포 함수(p) 근사화
- 문장 x , 단어1 x_1, ...., 단어n x_n

- ML에서의 MLE를 보면 P_data(y|x) : x(SMS)가있을 때 y(SPAM/HAM)에 속할 확률
- y label이 주어지므로 supervised learning
- 이를 신만이 아는 분포 p(y|x)로 approximate하는 방법은 세타를 이용하는 것 -> p(y|x,Θ)
8.2 RNN을 사용한 텍스트 분류
- 사실 CNN을 사용해서도 텍스트 분류가 가능은 함
다대일 사용 : 마지막 output tensor만 취함

Bidirectional multi-layered RNN사용
non-autoregressive 사용(문장 한꺼번에 넣을 수 있음)

마지막 output만 사용
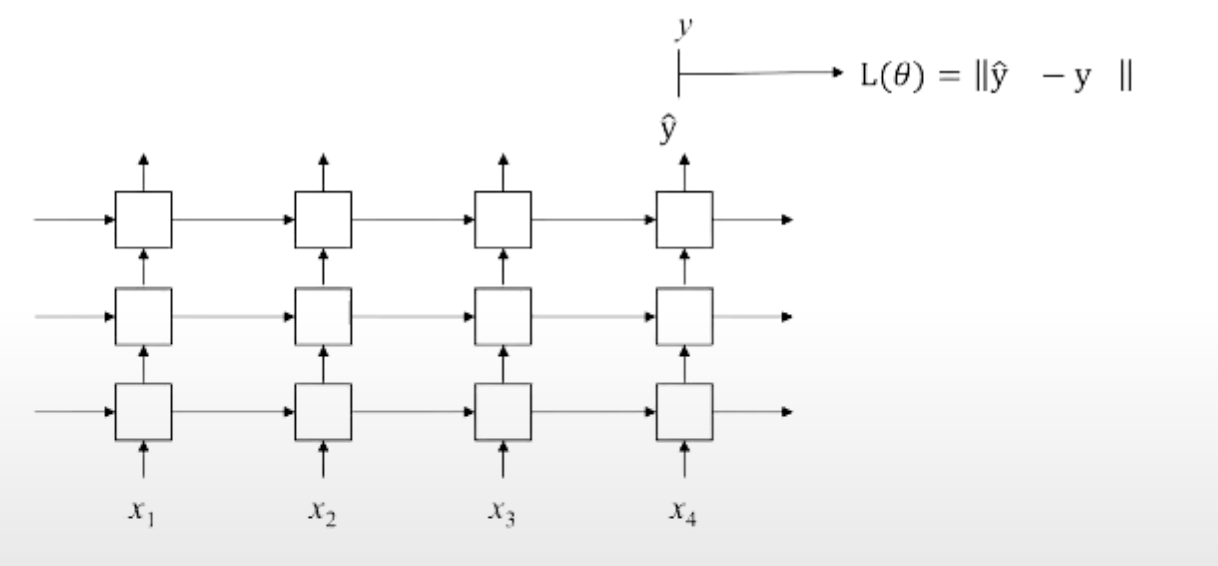
RNN 분류기 작동 방식 : Embedding Layer가 하나 더 들어감

- one-hot vector가 차원이 큼 -> embedding layer를 거치면 차원이 적절하게 줄어듦
- cross entropy loss 사용하여 loss function구현(이 역시 차이를 정의함)
Embedding Layer

- one-hot vectors : one-hot encoding방식으로 word vector를 표현한 것 (sparse)
- embedding layer weight를 곱해줌으로써 압축+의미(dense)
- fully-connected layer(linear 식)란?
- 해당 레이어의 row만 가져오므로 행렬곱이 필요 없음
- 최종 embedding vector가 RNN에 들어가 ŷ이 나오고 y와 비교하여 loss function계산이 이루어짐
RNN 분류기 내 텐서 관찰
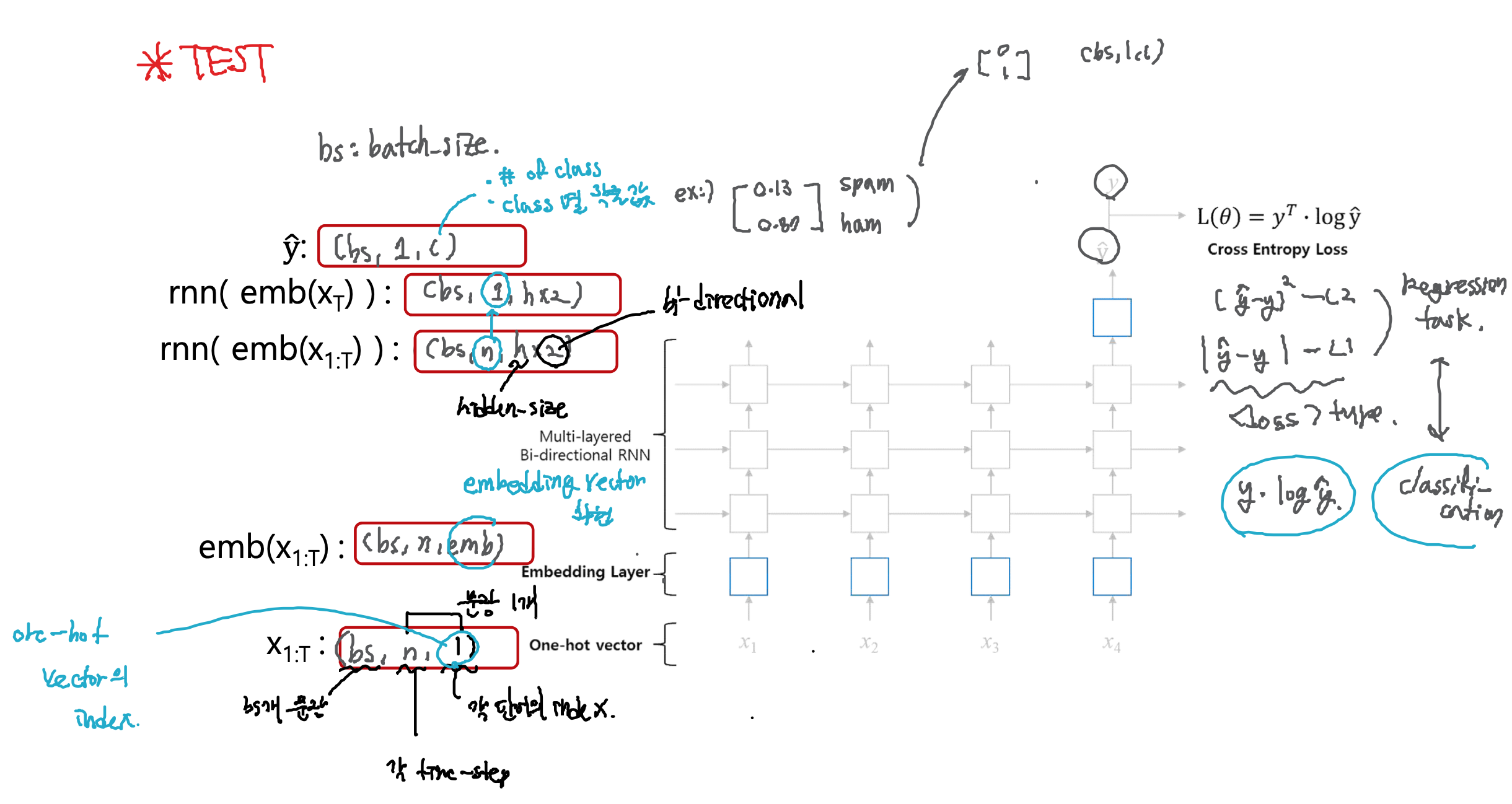
1. X_1:t(input_tensor) : batch_size(bs개의 문장), n(각 time-step), 1(input_size: 각 단어의 인덱스)
2. emb(X_1:t) : batch_size(bs개의 문장), n(각 time-step), embedding_size(embedding vector의 차원)
3. rnn( emb(X_1:t)) : batch_size(bs개의 문장), n(각 time-step), hidden_size x 2(bi-directional)
4. rnn( emb(X_t)) 마지막 time_step만 취함 : batch_size(bs개의 문장), 1, hidden_size x 2(bi-directional)
5. ŷ : batch_size(bs개의 문장), 1, number of class(class별 확률 값)==정답레이블
요약
Non-autogressive task이기 때문에 입력을 한 번에 받아도 됨
- 모든 time-step에 대해 병렬 처리 가능
Feed-forward 과정
1. one-hot vector를 embedding layer에 입력
2. Embedding vector를 RNN에 넣고 출력 얻음
3. RNN의 출력 중 마지막 time-step의 값만 취함
4. 취한 값을 softmax layer에 통과하여 각 카테고리의 확률 값 얻음
'인공지능(AI) > 자연어처리(NLP)' 카테고리의 다른 글
| [NLP 개념] 언어모델(Language Model) (0) | 2021.05.03 |
|---|---|
| 01 자연어처리 소개 (0) | 2020.12.17 |
| 06 순환 신경망(RNN) (0) | 2020.12.16 |
| 05 어휘 분석 (0) | 2020.12.16 |
| 04 텍스트의 전처리 (0) | 2020.12.15 |