![[Programming Language Pragmatics] 07 Data Types(1)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbzASDa%2FbtqP0tY4wkU%2FAAAAAAAAAAAAAAAAAAAAAFPugh3MafcAbZSXx643elFJYbILx9OlOMOrxQeeouZt%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3DIJq2Q0fB8Y6BqIoFzqgpQvh9SQg%253D)

[07 Data Types(1)] 7.1~7.2
Table of Contents
7.1 Type Systems
- 7.1.1 Type Checking
- 7.1.2 Polymorphism
- 7.1.3 The Meaning of “Type”
- 7.1.4 Classification of Types
- 7.1.5 Orthogonality
7.2 Type Checking
- 7.2.1 Type Equivalence
- 7.2.2 Type Compatibility
- 7.2.3 Type Inference
- 7.2.4 The ML Type System
7.3 Parametric Polymorphism
7.4 Equality Testing and Assignment
7.1 Type Systems
대부분의 프로그래밍 언어들은 타입을 가지고 있음
타입의 목적
프로그래머가 context를 explicit할 필요 없이 타입은 많은 연산자들을 위한 implicit context를 제공함
- In C, 표현식 a + b 는 두 변수가 정수 타입일 경우 정수 덧셈으로 사용됨
- 만약 두 변수가 double/float 타입일 경우 floating-point 덧셈임
- Pascal에서 new p는 heap과 p를 가리키는 포인트로부터 storage의 블럭을 할당 받음(p가 가리키는 공간만큼 할당)
- In c++, Java, C#에서는 new my_type()만이 공간할당을 하는 연산자는 아님; 사용자 정의 초기화 함수를 사용할 수도 있음
타입은 semantically valid program안에서 수행될 수 있는 연산자의 set을 제한할 수 있음
- 프로그래머가 character에 record를 더한다면, 둘의 타입이 다르므로 컴파일러에서 막음
- 좋은 타입 시스템은 실무에서 많은 실수를 잡아낼 수 있다
- explicit type 구체화는 프로그램의 가독성이 좋아짐
- 만약 타입을 컴파일 타임 때 알게 된다면, 최적화 작업도 가능해짐
컴퓨터 하드웨어는 몇몇의 다른 방법으로 메모리 안의 비트를 다루고 있음: 명령어, 주소, 부동소수점 등
- bit는 untype임 : 하드웨어는 어떤 타입이든간에 관련 안함
- 어셈블리어 역시 타입이 중요하지 않음
- 고급언어에서는 대부분 항상 값에 타입을 연관지어야 하고, 이는 에러 확인시 contextual information을 제공한다
타입 시스템의 구성요소
- 특정 언어 구조에 타입을 정의하고 연동시킴
- type equivalence(같은지/다른지), type compatibility(호환성), type inference(유추성)에 대한 규칙이 있음
타입은 값을 가지거나 혹은 값을 가진 객체를 참조할 수 있는 경우의 언어 구조이다
- named constant(상수), variable, record fields(구조체), parameters, subroutines 등을 포함
- 더 복잡한 표현식도 포함 되기도 함
타입 시스템 제 3 규칙
1) type equivalence(같은지/다른지) : 두 개의 값을 가진 타입이 같은지
2) type compatibility(호환성) : 두 개의 다른 타입을 같이 사용할 수 있는지
3) type inference(유추성) : 표현식의 결과의 타입을 유추
언어에서 변수 혹은 파라미터의 다형성은 레퍼런스의 타입 혹은 포인터와 객체의 타입인지 구별하는 것은 중요하다
서브루틴은 일부 언어에서 타입으로 고려되기도 함(그렇지 않은 언어들 역시 있음)
- first/second-class value인지 구분
*first-class value : 변수에 저장할 수 있음/함수에 전달 가능/함수에 결과값으로 반환 가능
*second-class value : 함수에 전달 가능 외 1개만 가능
- 파라미터의 개수, 파리미터 종류가 정해져있는 함수
- statically scoped language는 절대로 서브루틴을 동적으로 참조해서 생성할 수 없음
7.1.1 Type Checking
Type Checking이란 언어의 타입 호환성을 프로그램이 허락하는지에 대한 보증 과정이라고 생각하면 됨
- 규칙 위반일 경우 "type clash"라고 함
- 언어들은 strongly typed 함
- statically typed란 strongly typed 하며 type checking은 컴파일 때 수행됨
- 몇몇 언어들에서만 statically typed함
- 일반적으로 이 용어는 대부분의 타입 확인을 컴파일 때 수행하고 나머지만 런타임 때 수행하는 것을 말함
1970년대 중반 이후에 만든 언어들은 대부분 strogly typed이다
: C언어는 계속 발전하면서 strongly typed을 지향하는 방향으로 감
Meaning of "Type"
세가지 다른 관점이 존재 : denotational, structural, abstraction-based
Denotational point of view
- 타입은 단순히 값을 나타냄
- 어떤 범위안에 있는 것을 기준으로 타입을 할당(int : -2^256~2^256)
Structural point of view
- built-in types(integer, character, Boolean, real), composite type(record(structure), array)
- Algol W, Algol 68, 많은 언어들의 charecteristic이 1970s, 19080s년대에 디자인 됨
Abstraction-base point of view
- type을 operation들의 set으로 구성된 인터페이스로 봄; well defined & mutually consistent semantic
- Simula-67, Smalltalk과 현대 객체 지향 언어들의 characteristic
- 또한 다른 다양한 언어의 모듈 구조 안에서 찾을 수 있고, 대부분의 언어에서 프로그래밍 규율의 중요한 요소로 채택된다.
7.1.2 Polymorphism
Polymorphism이란 하나의 타입으로 다른 다양한 타입을 표현할 수 있음
- 공통적인 특성을 가지고 있는 타입임
- Parametric polymorphism : generic, templit
- Subtype polymorphism : T의 extension, refinements 타입(부모-자식)
Explicit paremetric Polymorphism은 제네릭을 말하며, 보통은 statically typed language에서 나타난다
implicit version은 컴파일 타임 때 구현되며 주로 ML-family 언어에 속한다 : dynamic typing, 런타임 때 체크
Sybtype polymorphism은 객체지향 언어에 포함 됨
- 부모 자식간의 상속관계를 만들어냄
- static typing과 함께 일어날 경우, 대부분의 작업이 컴파일 때 수행되는 다양한 타입들을 다루는 과정이 필요하다
- C++, Java, C#등 대부분의 언어들은 제네릭을 위한 분리된 메카니즘을 제공허며 컴파일 시간 때 체크한다
- 서브타입과 parametric polumorphism의 조합이 존재하는 이유며, List<T>, Stack<T> 등 유용하게 사용
이와 반대로, Smalltack, Python, Ruby 등을 포함하는 dynamically typed obkect-oriented language들은 parametric, subtype polymorphism 을 한 가지 메카니즘으로 다루고 런타임때 타입 체킹이 일어난다.
7.1.3 Orthogonality
Otrhogonality(일관성)은 타입 시스템 디자인에서 중요하다
- higly orthogonal languge는 해당 언어를 배울 경우 다른 언어에서도 비슷하게 응요 가능함
- Algol68, C는 statement와 expression을 구별하는 것을 제거해 orthogonality를 높임
- C, Algol68의 경우 예를 들어서, return type이 void로 일반적으로 선언된 procedure의 개념으로 함수가 사용될 수 있다.
- 만약 프로그래머가 특정 값을 반환하는 함수를 호출하지만 반환 값이 필요하지 않을 때, C언어에서는 void 로 캐스팅해 해당 값을 버릴 수 있다.

- trivial type이 없는 언어일 경우, 반환 값이 있는 함수는 반드시 아래처럼 붙여줘야함(C언어에 비해 덜 Orthogonal함)
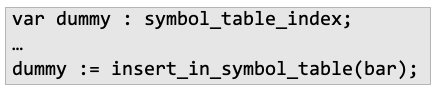
Otrhogonality의 또다른 예제
- 변수의 값을 지우는 경우를 고려해보자
- 포인터 타입의 경우 종종 null값을 저장해둔다
- enumeration의 경우 "none of the above"라고 추가해줌
- 이러한 두 가지 테크닉은 매우 다른 개념인데, underlying implementation안에서 모든 변수의 비트 패턴의 사용을 미리 만들어 두는 등의 타입 일반화를 하지 않는다
- composite type, 또는 aggregate등의 객체를 위한 구체화된 literal value
- 이들은 static 자료 구조의 초기화를 위해 특별히 소중하게 다뤄진다 : 만약 없을 경우, 프로그램은 런타임때 초기화 수행을 위해 시간낭비를 할 것
"none of the above" 등의 예제를 더 orthogonal한 방법으로 사용하고자, 많은 함수형 언어들과 몇몇의 절차지향 언어에서 Option 혹은 Maybe라고 종종 불리우는 스페셜 타입 생성자(construct)를 사용한다
In OCaml에서 아래와 같이 쓸수 있음

다른 다양한 언어들에서 Option type이 나타나기도 함. (Haskell, Scala, C#, Swift, Java, c++)

Ada에서는 모든 구조화된 타입을 위해 aggregate를 제공한다

아래와 같이 할당문을 쓸 수도 있음

7.1.4 Classification of Types
- 타입에 대한 용어는 언어마다 다르다(float, real 등 실수형에 대해 다양한 이름이 존재)
- 공통적으로 많이 쓰이는 타입 언어들을 살펴보자
- 대부분의 언어들은 대부분의 프로세서에 의해 하드웨어 안에서 지원하는 빌트인 타입을 제공한다
: integers, characters, Booleans, real (floating-point) numbers
- Boolean(또는 Logical)은 특별히 1 은 true, 0은 false로 표현되기도 한다.
- 캐릭터 타입은 전통적으로 1바이트로 크기가 정해져 있으므로 특히 ASCII encoding 기반이다
- 가장 최근의 언어들로는 Unicode character set을 지원하기 위해 2바이트로 설정(Java,C#,etc)
- Fortran2003의 경우 4바이트 유니코드 캐릭터를 제공한다
Numeric Types
- 기본적인 숫자 타입
- 일부 언어에 있어서 정수와 실수를 구별해서 범위를 따로 주기도 한다(C, Fortan)
: 정수 (int < long < long long) 실수 ( float < double < long double)
- 이런 경우 효율성은 좋으나 이식성(portability)이 좋지 않음
- 일부 언어들은 signed/unsigned를 구별한다(C계열, Modular계열)
- 몇몇의 언어들은 빌트인 복소수 타입을 제공하기도 함(Fortan, C99, Common Lisp, Scheme)
- integers, Booleans, character들을 discrete type(이산 타입) 혹은 ordinal type이라고 함
- discrete, rational, real, complex type등을 scalar type 혹은 simple type이라고 한다
Enumeration Types
- enumeration은 Pascal로부터 처음 만들어짐
- 가독성이 있는 프로그램을 위해 만들어졌으며, 컴파일러가 프로그래밍 에러의 특정 종류를 찾기 위해 만들어짐
- 명명된(이름이 붙여진) 원소들의 집합의 구성을 enumeration type이라고 함
Enumeration type : In Pascal




Enumeration type : In C
- enum keyword 사용
- 단순히 정수로 표현됨


Pascal, 대부분의 계승언어는 반대로, enumeration과 정수타입의 상수의 집합 사이의 차이는 훨씬 더 큼
- enumeration은 정수와 compatable하지 않음, 즉 C언어보다 type에 훨씬 엄격함
- integer, enumeration을 혼용해서 쓸 경우 컴파일러가 오류를 발생시킬 수 있음
- 많은 언어들에서 built-in function을 제공해 enumeration value를 ordinal value로 바꿔주거나 그 반대도 성립하게 해줌
: Ada에서는 conversion employ로 pos , val이 존재
- 일부 언어들은 프로그래머가 enumeration type에 대한 ordinal value를 specify하는 것이 가능하다
C, C++, C# 등은 아래와 같이 사용될 수 있음

최근 버전의 자바는 아래와 같이 값을 지정하는게 가능

- Pascal, C는 같은 스코프내에서 두개 이상의 같은 이름을 가진 enumeration type이 존재할 수 없음
- Java, C#은 이를 가능하게 만듦
- Ada 같은 경우에는 프로그래머가 조금 더 편하게 이름만 가지고 추론이 컴파일러가 가능할 경우 허용해줌
- C++11의 경우 Java, C#의 enumeration을 흉내내는 방식으로 집어넣음
예)

Subrange Types
- subrange는 Pascal에서 처음 소개되었고 이후에 많은 언어들에서 사용
- subrange는 discrete base type의 값들의 인접한 subset으로 구성되어 있는 값이다
- Pascal과 대부분의 계승 언어에서는, subrange를 integer, characters, enumerations 와 심지어는 다른 subrange로 선언 가능
In Pascal

In Ada

- ... 는 Ada에서 범위를 나타내는 정의로 type constraint라고 함
- 해당 예에서는 test_score 은 derived type이고 정수타입과 호환가능하지 않음
- workday의 타입은 contrained subtype이다
subrange를 만드는 것의 장점
- 가독성이 좋은 프로그램을 만들 수 있음
- 컴파일러가 코드를 생성할 때 최적화 작업이 가능함
Composite Types
- nonscalar type들을 composite type이라고 부름 : 숫자가 아닌 타임
: Aggregation(구조체 등)
- 주로 constructor(구조체 , 배열 및 타입을 정의하는 방법, OOP에서 말하는 생성자x)를 가지고 생성하는 것들을 가리킴
- 가장 흔하게 볼 수 있는 composite type으로는 record(structure), variant records(unions), arrays, sets, pointers, lists, files 등
record(structs)
- Cobol에 의해서 소개된 개념
- fields(변수)의 collection으로 구성된다
variant records(unions)
- 항상 오직 한개의 variant record's fields만 유효
arrays
- 가장 흔하게 볼 수 있는 composite types
- index를 사용해 멤버간 구별을 지음
- string을 배열로 처리하는 언어가 있음(In C)
sets
- Pascal에서 소개된 개념
- set type은 base type이 있어야 함(일반적으로 discrete 함) : 각기 다른 값들을 포함함
Pointers
- 포인터는 l-value임
- 포인터 값은 포인터 베이스 타입의 객체를 참조함
- 포인터는 종종 주소값으로 구현됨(단, 항상 주소값으로 구현되는 것은 아니다!)
- recursive data type을 구현하는데 자주 쓰임
Lists
- 원소의 나열로 구성되어 있으며 Mapping, indexing의 개념을 가지고 있지 않음
- 보통은 길이가 정해져 있지 않은 경우가 일반적임
files(pass)
7.2 Type Checking
- statically typed languages(대부분의 경우에 컴파일 때 체크해주는 언어)에서는 객체의 모든 정의가 반드시 객체의 타입을 지정하게 되어있음
- 이 경우 우리는 type equivalence, type compatibility, type inference에 대해 이야기해 볼 수 있음
type compatibility는 프로그래머에게 있어 가장 고려해야할 상황임
- 어떤 특정 타입의 오브젝트는 특정 context에서 사용될 수 있는지에 대한 논의
- 가장 최소한으로 따졌을 때, equivalent라는 말이 나오면 compatibility함( equivalent < compatibility가 더 큰 범위)
- 그러나 많은 언어들에서 compatibility가 equivalent보다 루스한 관계를 가짐(타입이 달라도 compatibility할 수 있음)
type compatibility에 대한 논의로는 다음과 같이 세 가지 주제로 이야기 해볼 것임
1) type conversion(casting)
: 강제 형번환
2) type coercion
: 자동 형변환
3) non-converting type casts
: 어떤 타입에 대한 비트를 다른 값으로 표현하는 경우
어떤 표현식이 있을 때 더 작게 서브 표현식으로 나누었을 때 각각의 타입이 존재할텐데, 결론적으로 전체 표현식의 타입은?
- 타입 추론에 의해서 해당 질문은 답할 수 있음
- ML, Miranda, Haskell에서 타입 추론은 굉장히 중요한 역할을 한다 : 타입을 선언이 optional하므로 프로그래머가 타입 선언을 생략할 경우 컴파일러가 추론해야 함
7.2.1 Type Equivalence
사용자가 새로운 타입을 정의하는 것을 허용하는 언어에서는 다음과 같이 defining type equivalance의 두가지 규칙이 있다
Structural equivalence : 구조적 동일성
- 타입 정의에 있는 내용에 집중(메모리에 데이터가 어떻게 들어 있는지)
- 대략적으로 말하자면, 내용물이 같은 것들로 구성되어 있을 때 두 타입이 같다고 함
- Algol 68, Modula-3, C, ML이 해당
Name equivalence : 정의가 같은지 확인
- 타입 정의의 lexical occurence(코드 상에서 어떻게 나타나는지)에 집중
- 대략적으로 말하자면, 각각의 새로 만들어내는 케이스(사용자 정의)를 새로운 타입을 만들어 낸다고 생각하면 됨
- 자바, C#, Standard Pascal, Ada를 포함한 파스칼 계승 언어들
structural equivalence는 언어마다 정의가 조금씩 다름
파스칼 계열의 언어들은 structural equivalence상, 변수 선언 format에는 큰 차이가 없음(즉 동일한 타입이라고 인식)

- 대부분의 언어들이 같다고 봄
- 단, ML에서는 다르다고 봄
아래와 같이 파스칼 배열의 파스칼 표기법을 생각해보자

- 배열의 길이가 같고, 인덱스 value가 다를 경우에 둘이 equivalent하다고 할 수 있는가?
- 대부분의 언어에서는 다르다고 봄
- 단 Fortran, Ada의 경우에는 compatible하다고 봄(같지 않다고 보는 것은 동일)
structural equivalence는 메모리 구조 측면(low-level), 구현 관점에서 보면 더 직관적으로 볼 수 있음
- 해당 관점의 문제점은 프로그래머가 두 개가 다른 타입이라고 만들었는데 언어 입장에서는 동일한 타입이라고 오해를 할 수 있음
아래는 해당 경우의 예제
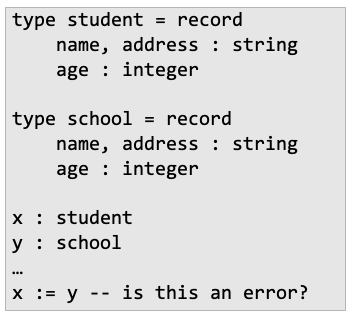
- record 안의 filed의 이름도 같고, 각 타입이 같은데 record의 변수 이름만 student, school로 다른 경우
- 컴파일러의 경우 이 경우 structurally equivalent 하다고 판단
- 즉 같은 타입으로 보므로 x := y 코드 부문에서 에러가 나지 않음
name equivalence는 해당 경우에 좀 더 보수적으로 봄
- 프로그래머가 두 개의 타입을 정의했다면 컴파일러가 다른 의미로 쓰여야 한다고 이해하게 하는 것
- 해당 경우의 위의 코드에서의 x,y는 타입이 다르다고 인식 : 애초에 x,y의 이름이 student, school로 다른 것도 참고하여 인식
Variant of name equivalence
- C언어에서는 typedef를 통해 새로운 이름을 붙여줄 수 있다(alias와 역할이 비슷)
아래는 Algol, C 코드

- 이 경우 새롭게 정의해준 이름과 이전 타입의 이름이 같은 것이라고 보는가?
아래의 경우 alias를 사용한 코드인데, 이 경우 두 타입을 서로 다르게 인식한다

- strict name equivalence : alias 타입도 다르게 봄
- loose name equivalence : alias 타입은 단순히 이름을 바꾼 것이므로 같은 타입으로 봄
- 대부분의 파스칼 패밀리는 이에 속함
- Ada에서는 strict/loose name equivalence 둘 다 지원 : derived type or subtype
- derived type은 호환불가능 : 즉 별개의 타입으로 봄
- subtype은 호환가능: 즉 같은 타입으로 봄
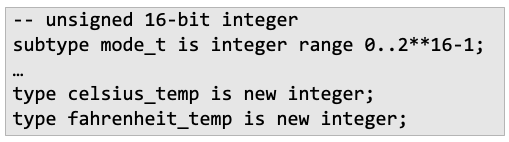
- strict name equivalence를 따른다고 하면, type A = B라고 선언할 경우 새로운 정의를 만든다고 봄
- 반대로 loose name equivalence를 따를 경우 A와 B가 같은 definition을 공유한다고 생각

- strict name equivalence: p,q와 같고 r,u가 같음
- loose name equivalence: r,s,u가 같음(p,q가 같은건 당연 | loose가 strict보다 더 루즈한 규칙)
* p,q와 t는 왜 다르다고 보는가? 서로 다른 라인에서 정의되었으므로
- structural equivalence: 여섯개의 변수가 다 같다고 봄
#11-#01 : 31:28~
7.2.2 Type Compatibility
7.2.3 Type Inference
7.2.4 The ML Type System
7.3 Parametric Polymorphism
7.4 Equality Testing and Assignment
- integer, floating-point numbers, characters 등 값으로 표현되는 비교적 간단한 타입인 primitive data type의 동일성 테스트와 할당을 단순하고 직관적임(bit-wise comparison or copy)
- 더 복잡해진, 추상 데이터 타입과 같은 경우에는 의미적으로도, 구현적으로도 더 복잡해진다
예를 들어보자. 문자열 s,t를 비교한다고 할 때 s==t라는 표현식을 쓴다고 하자
1. s,t가 alias로 표현된 것인가?
2. 각 문자열이 저장공간을 차지하고 있을 때 전체 공간에서의(full length) bit-wise가 동일한 가?
- 틀림! 대부분의 프로그램에서 이 같은 방식은 매우 low level에 해당함
3. 같은 문자 나열을 포함하고 있는가?
4. 출력했을 때 같은 모습으로 출력되는가?
많은 경우에서 equality의 정의는 l-values와 r-values 사이의 구별을 하는 것이 핵심이다
reference가 존재할 때, 동일하다는 것을 같은 객체를 가리킬때 같다고 할 것 인가/혹은 실제로 각 가리키고 있는 객체들이 내부적으로 같을 때 같다고 하는가
shallow comparison((객체를 참조하는 값을 비교)

- refer to the same object(int *p = 100번지 , int *c = 100번지, p와 c는 eqaul)
- a == b
deep comparison(객체 내용을 모두 비교)
- refer to equal object(int *p = 100번지 , int *c = 200번지, 100번지 = "hi", 200번지 = "hi", p와 c는 eqaul)
- In JAVA : a.equals(b)
절차지향 언어의 경우 할당 연산자는 deep하게도, shallow하게도 쓰일 수 있음
Under a reference model of variables
shallow assignment

- a = b : a가 b가 가리키는 오브젝트를 가리키는 형태
- 객체의 참조 값 또는 포인터 값 저장(복사)
- java, c/c++ 참조값 혹은 포인터
deep assignment

- copy본을 똑같이 만들어내는 경우
- 객체 내용을 전부 새로 복사
- 즉 문자열을 통째로 복사
- In java, a.clone()
- In c, malloc -> strcpy
Under a value model of variables
- shallow assignment에서 a = b는 b에 있는 값을 단순히 a에 복사
- 만약 value가 주소값을 가진 포인터일 경우 값이 복사(포인터가 가리키는 곳에 저장된 값)되지 않고, 주소값만이 복사됨
- 즉 저장된 결과가, 이 경우 shallow comparison 결과 동일하다고 볼 수 있음
대부분의 프로그래밍 언어는 shallow comparison, assignment를 제공
- 극히 일부로 파이썬, Lisp등에서 deep comparison을 제공하기도 함
Deep assignment는 매우 드물다
- 분산 컴퓨팅에서 remote procedure call(RPC) system에서 사용됨
사용자 정의 abstraction을 위해 언어에서 정의된 어떠한 메카니즘도 equality testing, assignment에 대해서 모든 경우에서 만족할 만한 결과를 낼 순 없음
'Computer Science > 프로그래밍언어론' 카테고리의 다른 글
| [Programming Language Pragmatics] 06 Control Flow(3) (0) | 2020.12.08 |
|---|---|
| [Programming Language Pragmatics] 06 Control Flow(2) (2) | 2020.12.06 |
| [Programming Language Pragmatics] 06 Control Flow(1) (0) | 2020.10.25 |
| [Programming Language Pragmatics] 03 Names, Scopes, and Bindings(3) (0) | 2020.10.23 |
| [Programming Language Pragmatics] 01 Introduction (0) | 2020.10.19 |