![[Programming Language Pragmatics] 03 Names, Scopes, and Bindings(1)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcatLuF%2FbtqIAPPvXKV%2FAAAAAAAAAAAAAAAAAAAAACmGcUkpzM0DjH6715vSjZTzztBFGA_f3QCwjqG-xDBc%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3DegIzcRc5NLhsvHoOjsTzaThh5Qc%253D)

(해당 강의노트는 Michael L. Scott의 [Programming Language Pragmatics : 4th edition] 책을 기반으로 작성되었습니다)
[03 Names, Scopes, and Bindings(1)] 3.0~3.2
Table of Contents
3.0. Abstraction
3.1. The Notion of Binding Time
3.2. Object Lifetime and Storage Management
- 3.2.1 Static Allocation
- 3.2.2 Stack-Based Allocation
- 3.2.3 Heap-Based Allocation
- 3.2.4 Garbage Collection
3.0. Abstraction
- Fortran, Algol, Lisp과 같은 초창기 언어들은 '고급언어'라고 부름
- 기존의 기계어들과 달리 하드웨어에서 syntax, semeantics이 훨씬 더 추상적이기 때문이다
- Abstraction은 두가지 보완적인 목표를 성취했다.
- 기계 독립성 : 특정 컴퓨터 아키텍쳐에 종속적이지 않고 독립적인, 이식성이 좋은
- 사람이 좀더 이해하기 쉬운 프로그래밍(사용자 친화적)
Names
- name이란?
- (변수들이)다른걸 표현하는 mnemonic character string(문자열)
- 대부분의 언어에서 Name은 식별자(identifiers)로 사용
- alphanumeric tokens : alphabet + number
- symbols like +(add), -(subtract)
- Name은 변수, 상수, 연산자 등을 참조함
- 메모리 공간에 있는 값들을 나타낼 수 있음
- 단어 추상화에 있어 문맥 속의 본질(두번째 의미임, 첫번째 의미는 표면상의 의미)을 나타냄
- 복잡한 프로그램에 있어 프로그래머가 이름과 연관시키는 과정으로 그것의 목적 혹은 기능을 떠올릴 수 있게 지어야 함
Abstaction
- 모든 부분적인 컴퓨터 구조의 디테일로부터는 분리된 언어
- Subroutine(function)은 Control abstraction임
- 함수는 프로그래머가 복잡한 코드 부분은 숨기고 간단한 인터페이스 부분만 보여주게 해줌
- Class는 Data abstactions임
- 프로그래머가 실제 데이터는 숨기고 비교적 간단한 연산자들로 표현가능하게 함
3.1 The Notion of Binding Time
Binding
- 바인딩이란?
- 이름과 그 이름이 붙는 것을 결합시키는 것
- 바인딩 타임이란?
- 바인딩이 만들어지는 시간으로 더 일반적으로는, 구현이 정해진 때를 일컬음
- 일반적으로, early binding time은 효율성을 증대시키는 것과 관련있다
- 반대로 later binding time은 유연성을 증대시키는 것과 관련있음
- 아래와 같이 매우 다양한 bound가 결정된 시간이 있음
Language design time, Language Implementation time, Program writing time, Compile-time, Link time, Load time, Run time
Program writing time & Compile time
- Program writing time: 프로그래머가 어떤 알고리즘, 자료구조 등을 쓸지 결정하는 시간
- Compile-time
- 고급언어의 특정 부분을 기계어로 매핑시키는 시간
- 데이터를 메모리에 레이아웃하는 과정
: i.e. 코드에서 malloc으로 할당한 변수는 실제 메모리 상에 heap영역에 저장됨
Link time
- 대부분의 컴파일러는 각각 컴파일하는 것을 지원한다
- 여러개의 모듈을 하나로 합치는 작업이 링커에 의해서 진행된다.
- The linker chooses
- 또다른 하나를 고려하여모듈의 전체적인 레이아웃을 고르고 inter module reference를 재해결한다
- 각각 컴파일할 시, inter-module 을 참조하여 재해결(이 역시 linker의 binding에 해당)
Load time
- 운영체제가 프로그램을 실행하려고 메모리에 올릴 때를 말함
- 과거, 초창기의 운영체제에서는 machine address를 골랐음
- 이는 아직 Load time이 완료되지 않은 프로그램 내에서의 object를 위함
- 현재 운영체제에서는 가상 주소와 물리주소를 구별한다
- 가상주소는 link time 때 결정됨
- 물리주소는 run time 때 바뀔 수 있음
- 프로세서의 메모리 관리를 하는 하드웨어에서는 가상주소를 물리주소로 바꿔준다
Run time
- 프로그램 시작부터 끝까지 전체를 묶어서 런타임이라고 함
- 변수의 값을 연동시키는 binding이 이루어짐
- Run time subsumes 프로그램은 아래와 같음
- 프로그램이 시작했을 때
- 모듈 엔트리 타임(진입 시간)
- elaboration time( declaration을 처음 발견한 시간 )
- Elaboration of a declaration은 storage allocation, binding process를 참고한다
- storage allocation, binding process: declaration이 실행되었던 코드를 포함할 때 발생
- 엔트리타임의 절차(== function), block entry time(== code block)
- expression evaluation and statement execution time, a subroutine call time
Static and Dynamic
- Static: 컴파일 시간에 결정됨(before run time)
- Dynamic : 실행되는 중에 결정됨(at run time)
- 컴파일러 기반의 언어들은 결정을 빨리 내릴 수 있어서 인터프리터 언어들에 비해 효율적임
- 순수 인터프리터는 프로그램이 실행될 때마다 반드시 declaration을 분석해야 함
- 최악의 경우에, 인터프리터는 서브루틴이 매번 호출될때마다 local declaration을 재분석해야 할 수도 있음
Early & Later binding times
- Early binding times : 대부분의 컴파일된 언어들로 좋은 효율성을 가짐
- Later binding times : 대부분의 인터프리터된 언어들로 좋은 유연성(flexibility)을 가짐
Binding Time and Language Design
: 몇몇 언어들은 컴파일 자체가 어려운데 이는 semantics(의미분석) 자체가 run time때까지 미뤄야 분석 가능할 때가 있기 때문
- 따라서 융통성과 언어를 강력하게 만들어야함
- 대부분의 스크립터 언어들은 타입을 체크하는 것을 런타임때까지 미루기도 함
- Polymorphism : 다형성
- 임의의 자료형을 참조하는 객체들은 임의의 이름을 가진 변수에 할당할 수 있다
- 프로그램이 이를 처리할 준비가 되지 않은 객체에 operator를 적용하지 않는 한 유연하고 범용적인 코드 작성이 가능하다
상속 및 오버라이딩(책에 없는 내용)
- 자바에서 동적바인딩 참고
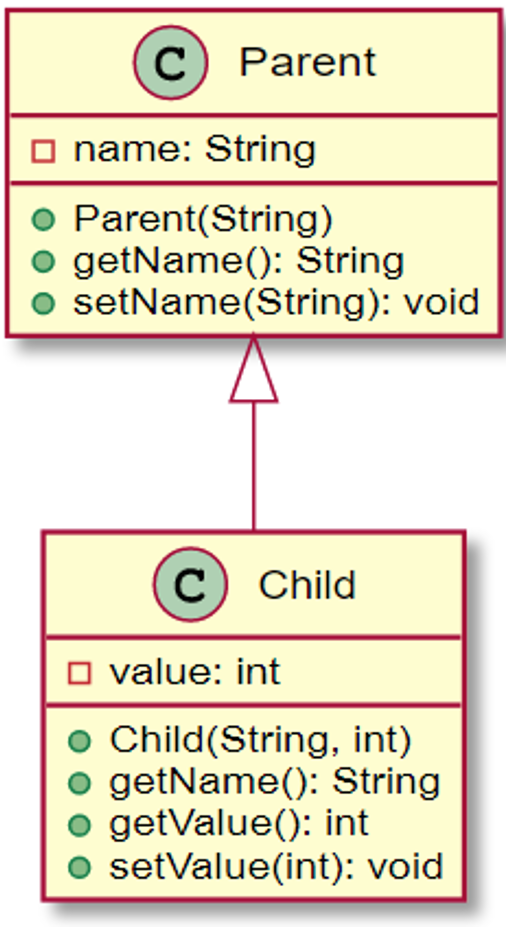
- Early binding
Parent p = new Parent("parent"); p.getName();
- 이 경우 Parent 클래스에 정의되어 있는 getName()함수가 호출됨 -> Early binding
- Late binding
Parent p = new Child("Child", 2019); p.getName();
- 이 경우 오버라이딩 된 child의 getName()함수가 호출됨 -> Late binding
- 자바는 기본적으로 Late Binding 방법을 채택
3.2 Object Lifetime and Storage Managements
: 이름과 바인딩 논의 시, 이름과 바인딩이 참조하는 객체를 구분하고 몇가지 key event를 식별하는 것이 중요
Key Events( 중요한 이벤트)
- 객체의 생성과 소멸
- 바인딩의 생성과 소멸
- 일시적으로 사용할 수 없게 되는 바인딩의 비활동과 재활동
- 바인딩을 사용하는 변수 참조, 서브루틴, 타입 등
Binding's Lifetime & Object's Lifetime
- 각 생애주기를 나타냄
- 두 생애주기는 반드시 일치할 필요는 없음
- Example
- 참조 호출: In C++, '&' use for reference operator.
- pass by value , pass by reference
- 변수와 파라미터의 이름 사이의 바인딩은 변수 자체보다 더 짧은 라이프타임을 가지고 있다.
-
예제 코드( In c++) // pass by reference
class Test { Test(int v) { value = v; } int value; int getValue() { return value; } }; void func(Test& v) { // pass by reference int c = v.getValue(); printf("value = %d\n", c); } int main() { Test t(5); func(t); printf("value = %d\n", t.getValue()); }: 위의 코드에서 변수 t는 메인함수가 종료될 때 소멸되지만 바인딩된 v같은 경우에는 func함수 종료시 소멸된다
-
예제 코드(In c++) // pass by value
class Test { Test(int v) { value = v; } int value; int getValue() { return value; } }; void func(Test v) { // pass by value int c = v.getValue(); printf("value = %d\n", c); } int main() { Test t(5); func(t); printf("value = %d\n", t.getValue()); }: 위의 코드에서는 변수자체와 바인딩된 것이 동시에 소멸함 즉 Test v는 v대로, Test t는 t대로 같은시간에 생성과 동시에 소멸
만약 name-to-object binding이 더 길다면?
- 아래와 같은 코드의 상황 가정이 가능하나, 사실상 버그임
void func(Test* v) {
int c = v->getValue();
printf("value = %d\n", c);
delete v;
}
int main() {
Test* t = new Test(5);
func(t);
printf("value = %d\n", t->getValue());
}
Object & Binding outlives binding
- Object outlives binding
- 바인딩이 사라진 객체의 경우 가비지가 될 확률이 높음
- Binding outlives binding
- dangling reference : 유효한 객체를 가리키지 않는 허상 포인터
객체의 생애주기는 일반적으로 객체의 공간을 관리하는데 사용하는 storage allocation mechanisms 원칙 세가지 중 하나와 상응한다.
- Static object는 프로그램이 실행될 때 전체 과정에 있어서 절대적인 주소 값을 가지고 있는 객체들
- Stack object는 서브루틴의 호출과 반환 시 생성되며 소멸되는 지역 변수들은 스택에 저장
- Heap object는 동적으로 할당되는 변수들
3.2.1 Static Allocation
Static objects
- 글로벌 변수들 - 스테틱 객체의 명백한 예제(but not the only one)
- 프로그램의 기계어로 구성되어 있는 명령어들 역시 static object에 해당
- C, C++에서의 스태틱 변수 예제 코드
void f() { static int n = 1; printf("n = %d\n", n); n++; } - 상수들과 string-valued constant literals 역시 스테틱하게 할당 됨
- A = B / 14.7 -> 14.7 이 상수
- printf("hello, world!"); -> hello, world! 는 스트링
- 대부분의 컴파일러는 디버깅, 동적 타입 체크, 가비지 콜렉션 등을 테이블로 생성하여 저장이 필요한데 이 역시 statical하게 할당됨
- Statically allocated object란 프로그램 실행 중에 값이 바뀌면 안되며, 수정하지 못하게 read-only memory에 보호되어 할당됨
지역변수들은 함수 호출시 생성되었다가 함수 반환시 소멸된다
- 만약 서브루틴이 반복 호출된다면 각각의 호출에서 각 지역변수들은 다른 공간에 생성과 소멸이 반복된다
- 언어 구현은 반드시 생성과 소멸 연산이 일어나는 런타임때 수행되어야한다.
Recursion은 Fortran에서 원래 지원하지는 않음(포트란90 이후에 추가된 것)
- 이전 Fortran 프로그램에서는 서브루틴을 오직 한 번만 호출이 가능했다.
- 컴파일러는 지역변수에 대해서 스태틱 할당이 가능했으며, 다른 호출 시에도 같은 공간 공유가 가능했다.
- 일부 Fortran 컴파일러는 지역 변수들을 위해 스택을 사용하는 것을 허용했으나 언어 자체의 정의는 recursion을 지원하고 있지 않아 static allocation을 대신 사용하는 것을 허용했다.
- 포트란 프로그래머들은 30년동안 recursion을 사용하는 것을 허용하지 않음
많은 언어에서 Named constant(변수인데 상수 취급받는 애들)는 컴파일 타임 때 결정되는 값을 가지는 것을 요구함
- 상수의 값을 지정하는 표현식에는 또 다른 형태의 상수나, 빌트인 함수, 혹은 산술 연산자만 사용할 수 있다.
- 이러한 종류의 named constant를 manifest constant 혹은 complie-time constant라고 한다
- 이러한 상수들은 항상 allocated statically될 수 있음
- 심지어, recursive subroutine에서는 지역 상수인것처럼 쓰일 수 있음
- 단, 상수를 매번 만드는게 아니라 똑같은 메모리 공간에 존재하게 된다.
다른 종류의 언어에서는 상수라는 개념이 단순히 초기화 이후에 값을 바꿀 수 없는 변수를 말한다.
-
C, JAVA, Ada가 이에 해당
-
해당 값들을 elaboration-time constant라 부르며, stack에 할당되어야 한다.
-
C#은 compile-time 과 elaboration-time constants를 const, readonly 키워드를 사용하여 구분함
-
예제 C&C#코드
// In C #include <stdio.h> void func(int n) { const int value = n; printf("value = %d\n", value); } int main(void) { int v = 3; const int t1 = 5; const int t2 = t1 + 8; func(v); return 0; }// In C# namespace ConsoleApplication1 { class Program { readonly int value; const int value2 = 5; Program() { value = 3; // value2 = 5; // 오류 발생 } // void setValue(int n) { value = n; } static void Main(string[] args) { } }}
3.2.2 Stack-Based Allocation
Recursion is allowed
- 한 언어에서 재귀성을 허용하면 동시에 존재해야 할 변수의 인스턴스 수가 개념적으로 제한되지 않기 때문에 로컬 변수의 정적할당은 더이상 옵션이 아님(즉, 꼭 해야함)
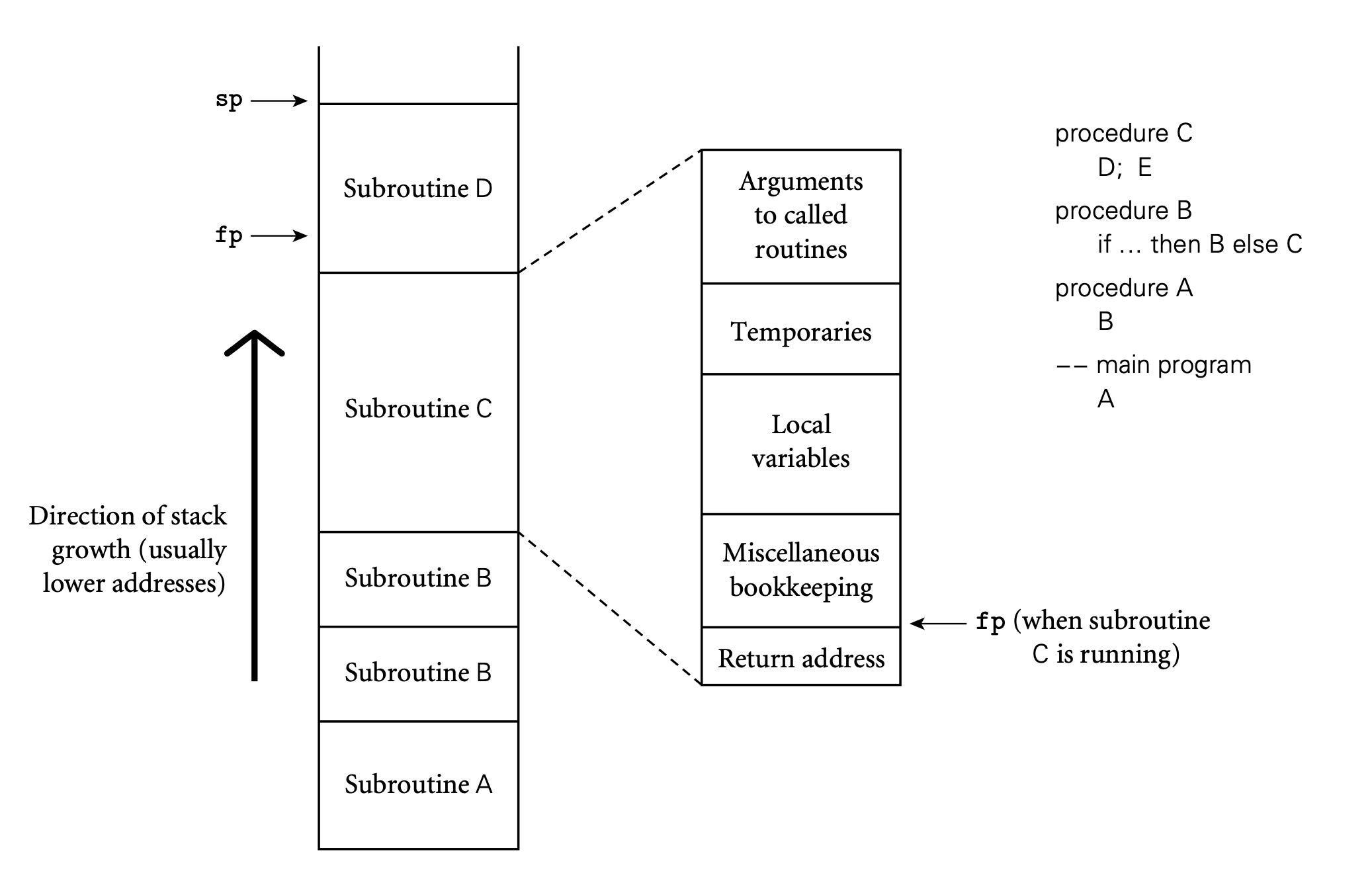
런타임 시 서브루틴의 각 인스턴스는 스택 위에 자신만의 frame을 가짐
- argumets, return values, local variables, temporaries, bookkeeping information을 포함함
- frame 을 activation record라고 함
- 해당 공간은 함수 호출 시마다 한 블럭씩 생성됨
- bookkeeping information : 서브루틴이 반환되는 주소, 레지스터 값들을 저장, calller의 스택 프레임을 참조하는 정보 등을 담고 있음
- callee : 호출되는 쪽
- caller : 호출자
- callee에서 쉽게 접근가능하도록 서브루틴에서 전달되는 인자는 프레임의 맨 위에 올라감
스택의 유지보수
- 스택의 유지보수는 서브루틴 자체의 호출 순서, 서브루틴의 프롤로그와 에필로그의 책임임
- prologue : code executed at the beginning
- epilogue : code executed at the end
- calling sequence
- 함수가 호출되기 직전과 직후에 실행되는 코드에 해당하는 부분
- 때때로, 이는 caller, prologue, epilogue의 혼합된 연산자들을 참조하기도 함
- prologue
- 함수가 호출되고 시작되는 부분에 실행되는 코드에 해당하는 부분
- epilogue
- 함수가 호출되고 끝나는 부분에 실행되는 코드에 해당하는 부분
stack frame은 컴파일 타임 때 결정 할 수 없음
- 컴파일러는 일반적으로 스택위에 준비되어 있는 다른 프레임들이 무엇인지에 대해 말할 수 없음
- 프레임 내에서의 객체의 오프셋(상대적인 위치, 주소)은 대게 static하게 결정될 수 있다
- 현재 프레임에 있는 지역변수에 접근할 때는 현재 있는 위치에 오프셋을 더해서 결정할 수 있다.
- 지역 변수, temporaries, booking information들은 특별하게 음수 오프셋을 가지게 된다
- 매개변수나 리턴 값은 양수 오프셋을 가지게 된다

recursion이 없는 언어인 경우, 스테틱하게 로컬변수를 할당하는 것보다 스택을 사용하는 것이 더 장점이 많다
- 많은 프로그램에서, 프로그램의 모든 서브루틴이 동시에 호출되지 않는다
- 현재 활성화된 서브루틴의 지역변수를 위한 전체 공간이 필요한데 이는 활성화 여부와 상관없이 모든 서브루틴을 담을만큼 전체공간이 충분히 크지 않는 경우가 많다
- 스택은 static allocation을 위해 요구되는 것보다 런타임때 요구되는 메모리가 더 적다.
3.2.3 Heap-Based Allocation
Heap
- 코드 실행중 임의의 시간에 할당 및 재할당 되는 동적할당 공간
- 동적으로 할당되는 자료구조와 충분히 일반적인 문자열을 위해 필요한 공간
- 이러한 힙 영역을 관리하기 위해서 많은 전략들이 존재 함 - 속도와 공간의 낭비를 고려하며 원칙을 세움
- 아래는 단편화 문제를 나타냄
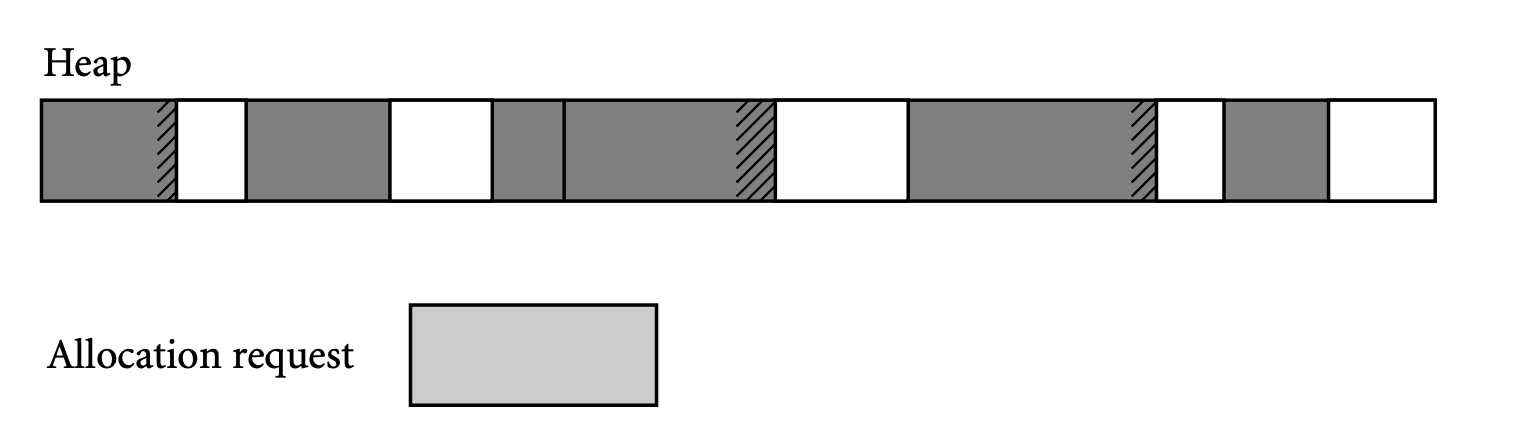
공간 관련 문제 : 내부 단편화와 외부 단편화
- 내부 단편화(internal fragmentation)
- 메모리 할당 시 프로세스가 필요한 양보다 더 큰 메모리가 할당되어서 프로세스에서 사용하는 메모리 공간이 낭비 되는 현상
- 외부 단편화(external fragmentation)
- 메모리가 할당 및 해제 작업의 반복으로 작은 메모리가 중간중간에 존재 즉, 여유 공간이 여러 조각으로 나뉘는 현상
많은 저장 관리 알고리즘이 현재 사용되지 않는 힙 블럭들의 단일 연결리스트를 유지한다.
- 처음에는 전체 힙블럭이 단일로 구성되어 있다.
- 각 할당 요청이 들어올 경우 적절한 사이즈의 블럭을 위해 리스트를 서치하는 알고리즘을 선택해야한다.
- First fit : 크기와 상관없이 제일 앞에 있는 리스트를 잘라서 줌
- Best fit : 전체를 탐색하고 할당을 원하는 메모리 공간과 차이가 가장 작은 리스트 공간을 할당해준다
- 만약, 요구된 것보다 더 큰 블럭을 선택했을 경우 사용된 공간과 사용되지 않은 두 공간으로 나누어질 것이며 이는 free list로 사용되지 않은 부분이 반환되게 된다
- 만약 사용되지 않는 공간이 minimum threshold보다 작게 되면 내부 단편화가 발생하더라도 떼어서 버려버린다.
- 블럭이 할당 해제되고, 프리 리스트로 반환될 시, 물리적으로 근접한 블럭들 중 하나 혹은 두개 모두 프리한지 아닌지를 체크하고 맞을 경우 이 블럭들을 합치게 된다
단일 프리 리스트를 관리하는 어떠한 알고리즘도 시간복잡도가 O(n) 정도 걸림(n = number of free list)
- 해당 시간복잡도를 상수시간으로 줄이고 싶으면, 각기 다른 사이즈들의 블럭을 위해 프리 리스트를 관리하는 방법을 사용 해야함
- 몇몇 알고리즘은 아래의 방법을 사용하여 공간을 관리함
- 예: 버디 시스템, 피보나치 힙
- 각 요청이 들어온 메모리의 크기를 스탠다드 사이즈로 반올림하고 공간을 할당함
- 힙은 pool로 분리됨, 각각 하나씩은 스탠다드 사이즈에 해당
Buddy System
- 2의 승수로 스탠다드 블럭사이즈를 설정하는 알고리즘
피보나치 힙
- 버디 시스템과 비슷하나 피보나치 수로 스탠다드 사이즈를 설정하는 알고리즘
외부 단편화의 문제점과 해결방법
- 문제점
- 요청을 충족하는 힙의 성능은 시간이 지남에 따라 낮아질 수 있다.
- 전체 필요 공간이 힙의 영역보다 작다고 하더라도, 요청이 충족되지 않을 가능성이 항상 생긴다.
- 해결방법
- 외부 단편화를 없애기 위해서 컴팩트하게 힙을 준비해야 함
- 힙을 컴팩트하게 하는 과정은 이미 할당된 블럭들을 움직여 남은 공간들을 하나로 합치면 됨
3.2.4 Garbage Collection
Heap-based object의 할당은 항상 프로그램 안에서 특정 연산자에 의해 일어난다
- 객체지향 언어에서 객체를 선택할 때
- 리스트에 마지막에 원소를 추가할 때(append)
- 이전의 short string 안으로 long value를 할당할 때
몇몇 언어에서 할당 해제는 프로그래머가 직접 요청해야 한다
- e.g., C, C++, Rust,
많은 언어들이 프로그램 내에서 더 이상 해당 변수가 사용되지 않는다고 판단될 시 자동으로 할당 해제를 지원함
- 더 이상 쓰지 않는 객체를 식별하고 반환을 위해 garbage collection mechanism을 제공함
Explicit Deallocaiton : 프로그래머가 직접 요청
- Pros
- 구현하기 쉬움
- 실행 속도가 빠름
- Cons
- 실제 프로그램 내에서 버그 비용이 높고 manual deallocation error가 흔함
- 객체를 너무 빨리 deallocate할 경우 dangling reference(허상 포인터)가 생길 수 있음
- 생명주기가 끝났음에도 해당 객체를 할당 해제하지 않았을 경우 memory leak 발생하고 heap 공간을 다 쓰게 됨
Garbage Collection : 프로그램 내에서 직접 제공
- Pros
- no menual deallocation errors
- 가비지 컬랙션 알고리즘이 향상되어, 런타임 오버헤드 발생을 줄임
- 요즘 만들어지고 있는 어플리케이션이 점점 커지고 복잡해지는 만큼 자동으로 메모리 정리를 해주는 것이 더 유용해지고 있음
- Cons
- 언어 구현의 복잡성을 높임
- 대부분의 정교한 가비지 컬랙터들이 특정 프로그램 내에서 막대한 양의 시간을 소비하고 있음
시간이 지나고, 많은 언어 디자이너들과 프로그래머들이 언어 특징의 필수로 자동으로 가비지 컬랙션해주는 것을 포함시키고 있음
- 가비지 콜랙션의 알고리즘이 향상하고 있음
- 런타임 오버헤드를 줄이고 있다.
- 언어 구현은 일반적으로 시간이 지날수록 더 복잡해지고 있음
- 자동 콜랙션의 복잡성은 점점 지엽적인 이야기가 되어가고 있음
- 요즘 어플리케이션들은 자동으로 메모리를 정리해주는 것이 더 유용함
'Computer Science > 프로그래밍언어론' 카테고리의 다른 글
| [Programming Language Pragmatics] 06 Control Flow(2) (2) | 2020.12.06 |
|---|---|
| [Programming Language Pragmatics] 06 Control Flow(1) (0) | 2020.10.25 |
| [Programming Language Pragmatics] 03 Names, Scopes, and Bindings(3) (0) | 2020.10.23 |
| [Programming Language Pragmatics] 01 Introduction (0) | 2020.10.19 |
| [Programming Language Pragmatics] 03 Names, Scopes, and Bindings(2) (2) | 2020.09.18 |