06 순환 신경망(RNN)

목차
6.1 기본 순환 신경망 Vanilla recurrent neural network, RNN
– 6.1.1 RNN 소개
– 6.1.2 RNN 구조
– 6.1.3 RNN 활용 사례
– 6.1.4 RNN 학습: Back-propagation through time(BPTT)
6.2 발전된 순환 신경망 Advanced RNN
- 6.2.1 그라디언트 소실 문제 (gradient vanishing problem)
- 6.2.2 Long short-term memory (LSTM)
- 6.2.3 Gated recurrent unit (GRU)
- 6.2.4 그라디언트 클리핑 (gradient clipping)
6.3 RNN 기반 자연어 생성 (PASS)
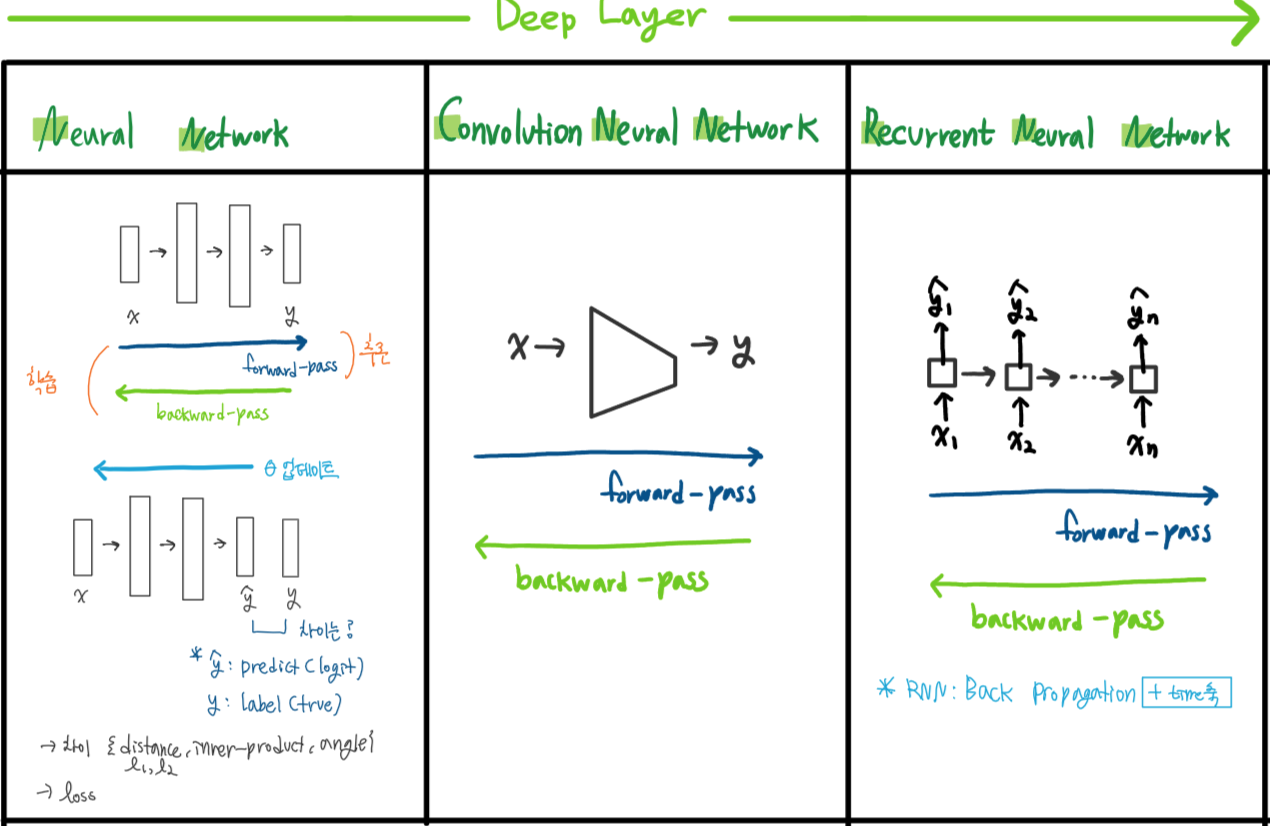
6.1.1 RNN 소개 : Recurrent neural network
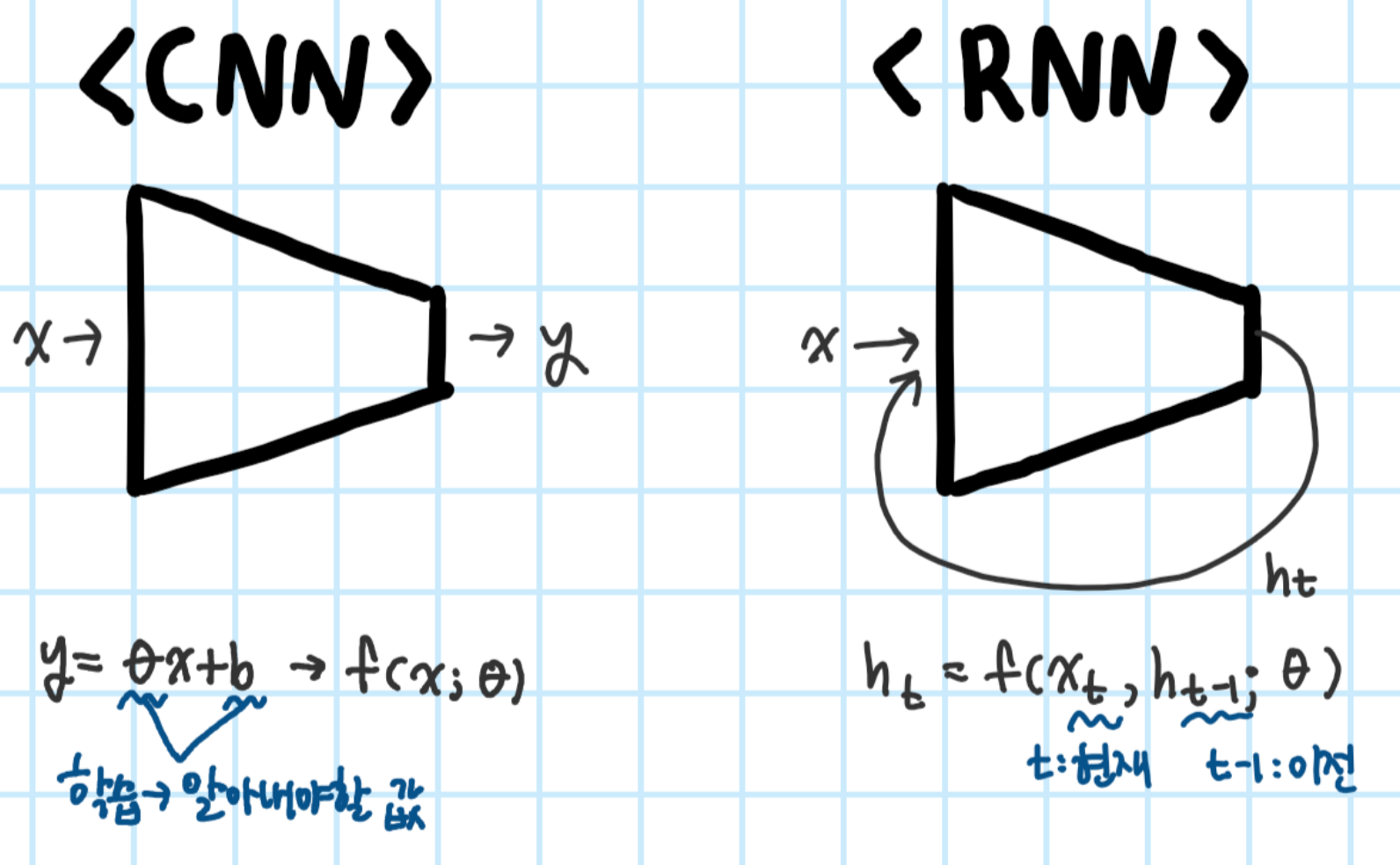
CNN vs. RNN
CNN(합성곱신망)
컴퓨터가 이미지를 이해하고 높은 수준의 추상화된 정보를 추출하는 인공신경망의 종류
데이터의 예 : 표형태의 데이터, 영상
RNN(순환신경망)
반복적이고 순차적인 데이터 학습에 특화된 인공신경망의 한 종류
데이터의 예: 연속 데이터, 시계열 데이터
- 타임 스탬프 유무에 따른 차이
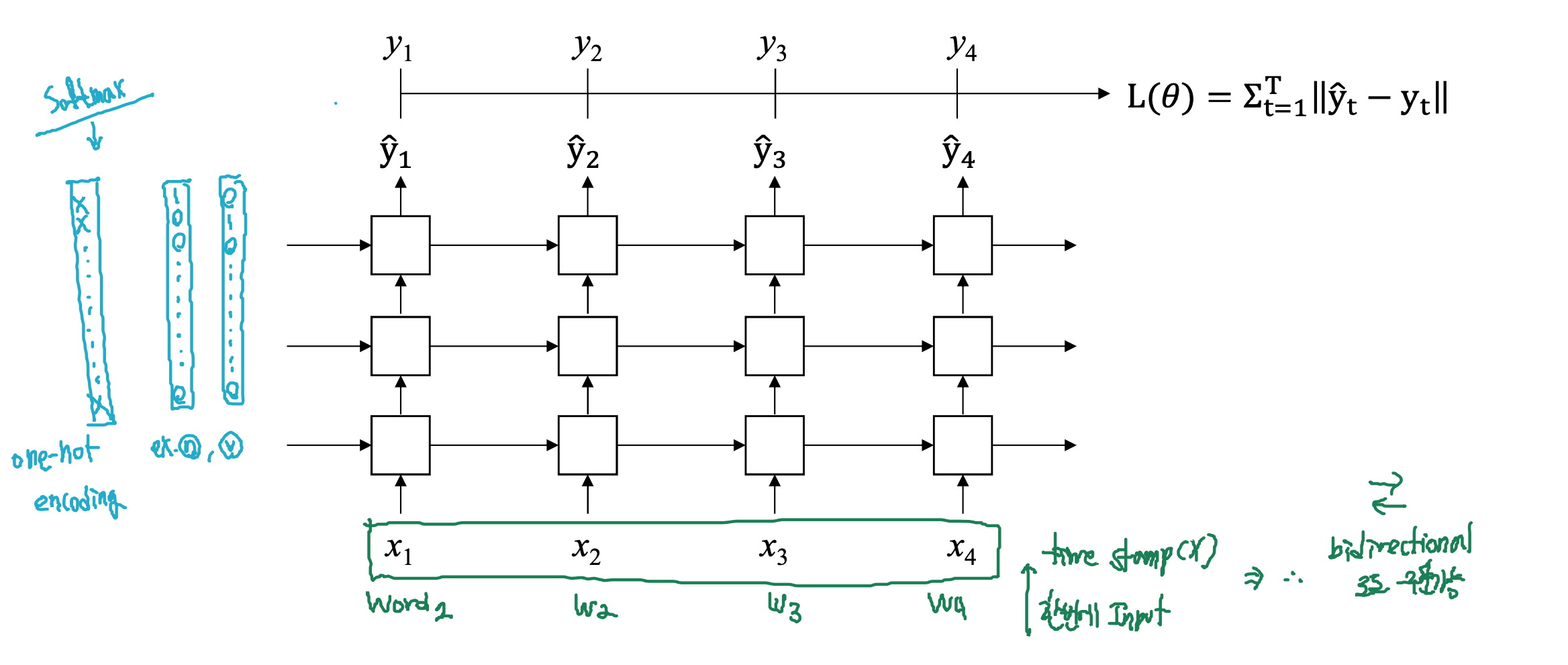
- 연속 데이터 : 데이터의 순서 정보가 중요, 텍스트 문장(단어의 순서), text, video, voice와 같이 샘플링 주기가 일정
- 시계열 데이터: 연속 데이터의 일종, 데이터가 발생한 시각 정보가 중요, 주식, 센서 데이터
6.1.2 RNN 구조
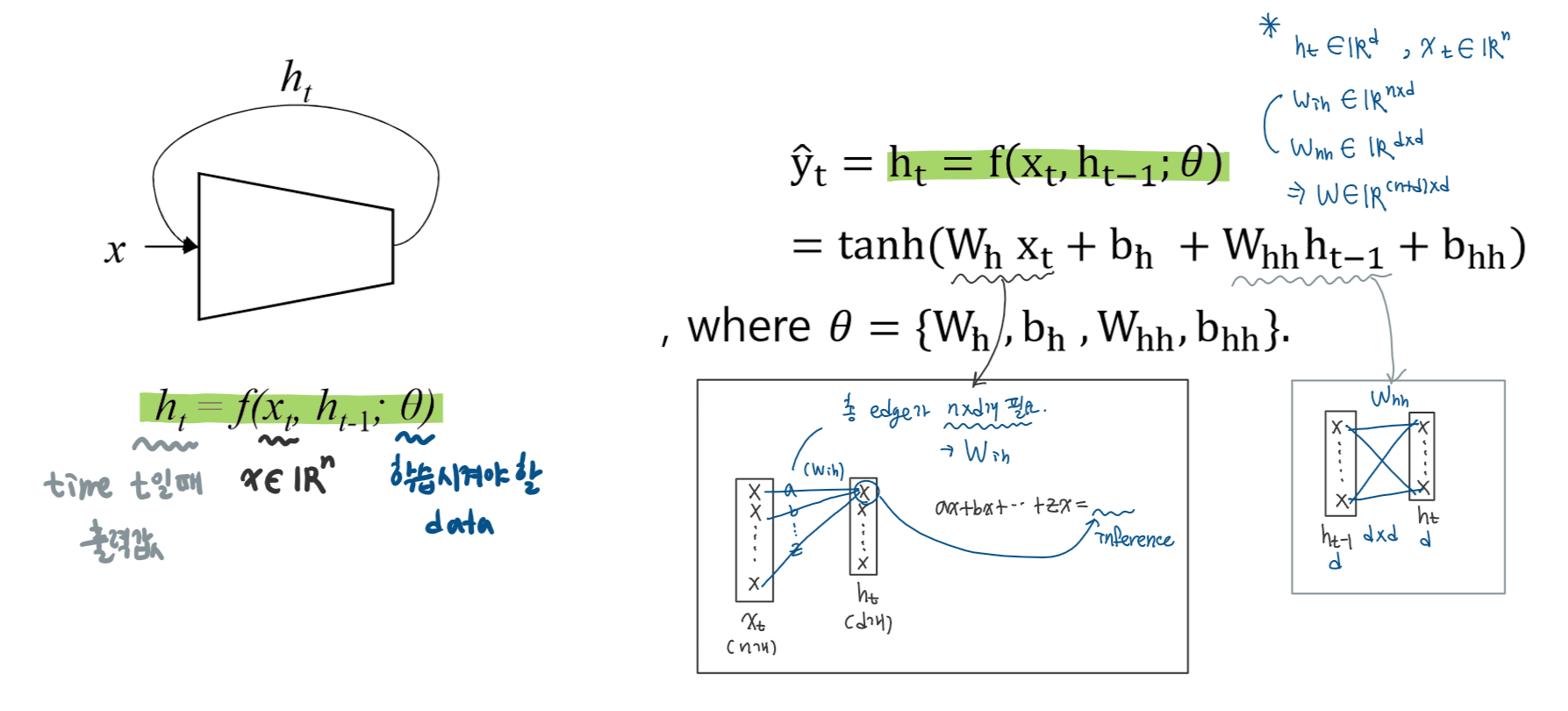
RNN 구조
RNN 구조의 다른 표현법 : Single Layered RNN

- t시간 동안 같은 세타를 사용(공유)
RNN 구조의 작동 방식

- 예측하는 값과 실제 정답사이의 차이를 줄이는 것이 목표
- 즉 loss function을 최소화하는 것
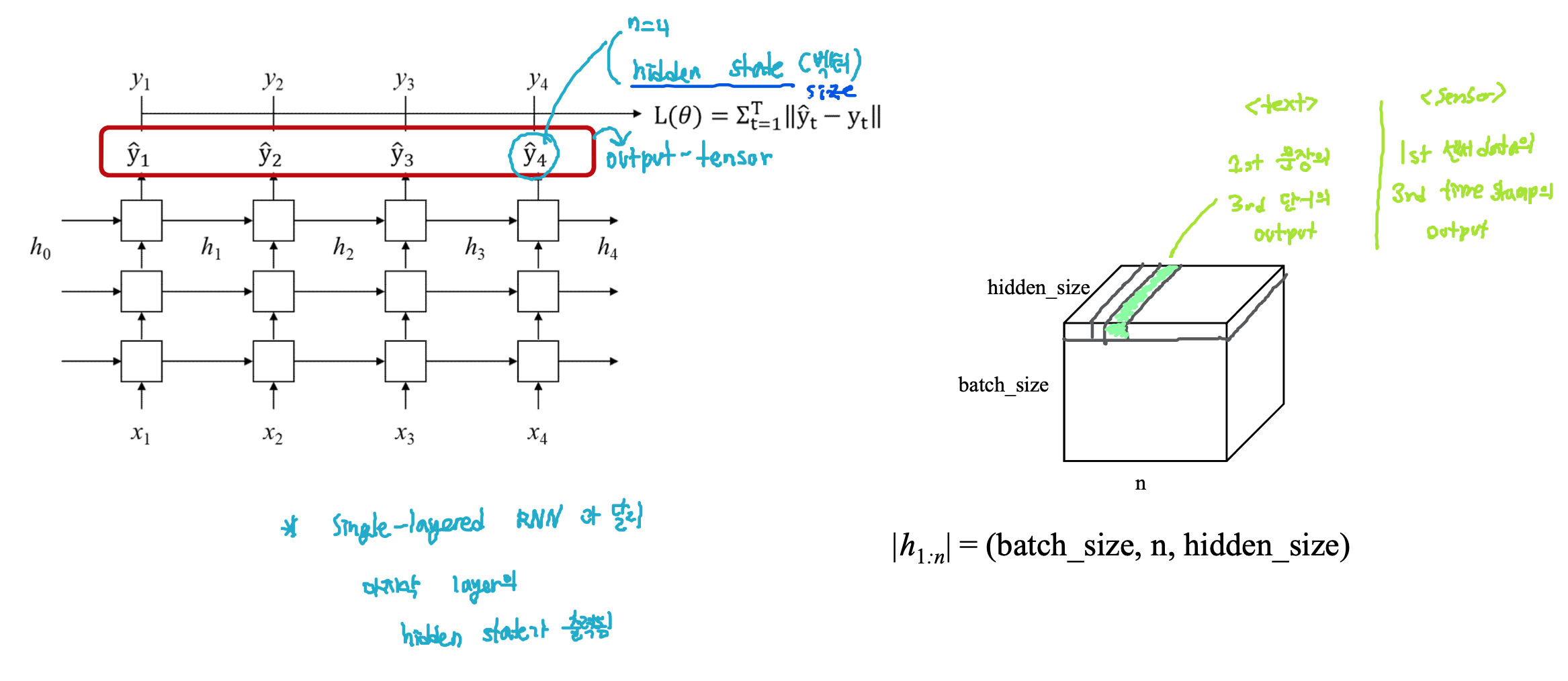
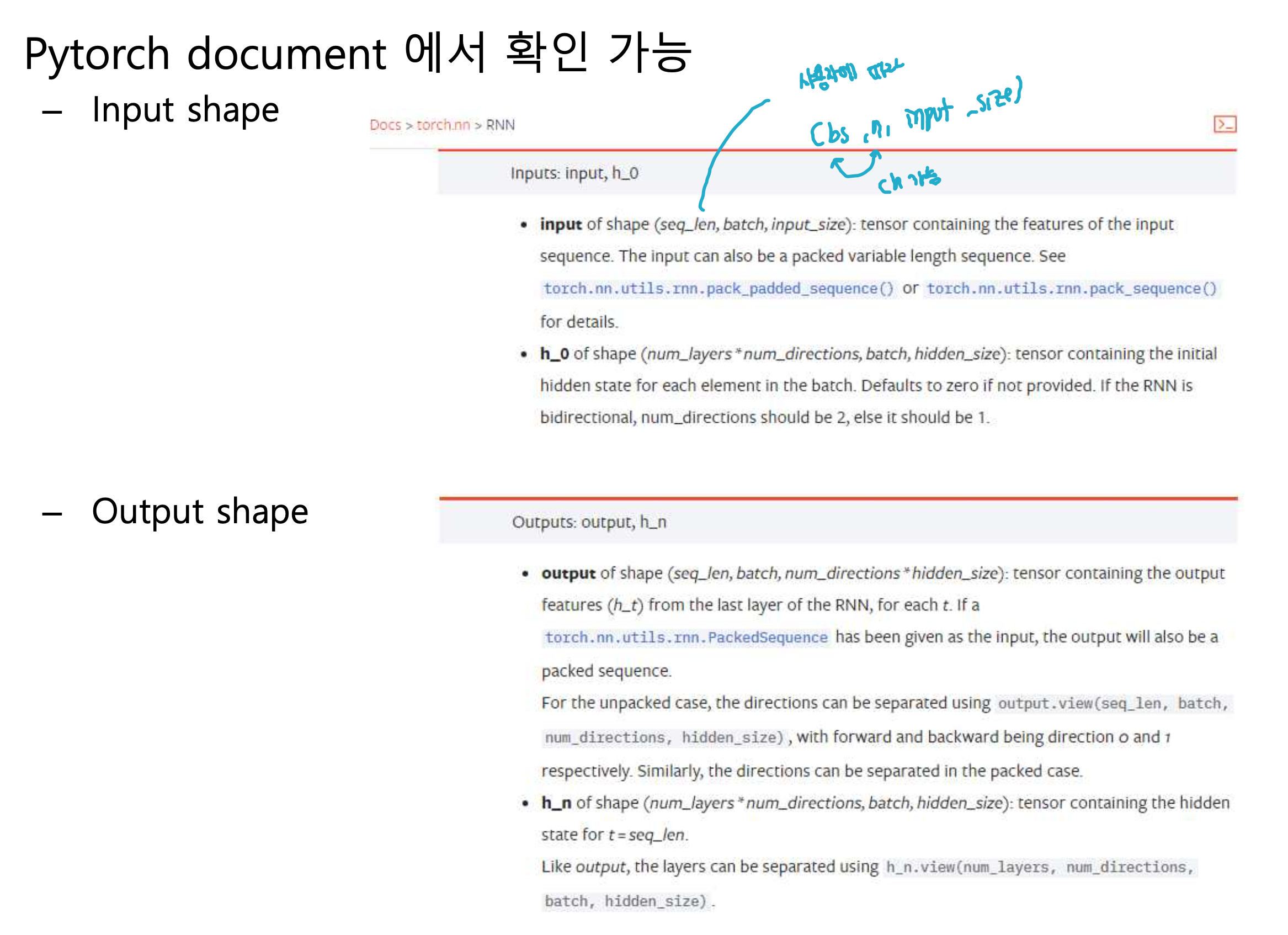
RNN 구조의 입력 텐서 : (batch_size, n, input_size)

RNN 구조의 출력 텐서 : (batch_size, n, hidden_size)

Multi-Layered RNN

- 시간을 기준으로 같은 세타를 공유, 단 층 별로는 다른 세타 공유
- hidden state : 각 층이 아닌, 모든 층을 합쳐서 결과 표현
Multi-Layered RNN: 출력 텐서 (batch_size, n, hidden_size)
- single layered RNN과 달리 마지막 레이어의 hidden state가 출력됨
Multi-Layered RNN: 은닉 상태 텐서 (number of layers, batch_size, hidden_size)

Multi-Layered RNN: 입력 텐서 (batch_size, n, input_size)

Bidirectional multi-layered RNN

- forward(정방향)
- backward(역방향)
Bidirectional multi-layered RNN : 출력 텐서 (batch_size, n, hidden_size x number of directions)

- bidirectional이므로 이 경우 출력 텐서는 (batch_size, n, hidden_size x 2)
Bidirectional multi-layered RNN : 은닉 상태 텐서
(number of directions x number of layers, batch_size, hidden_size)
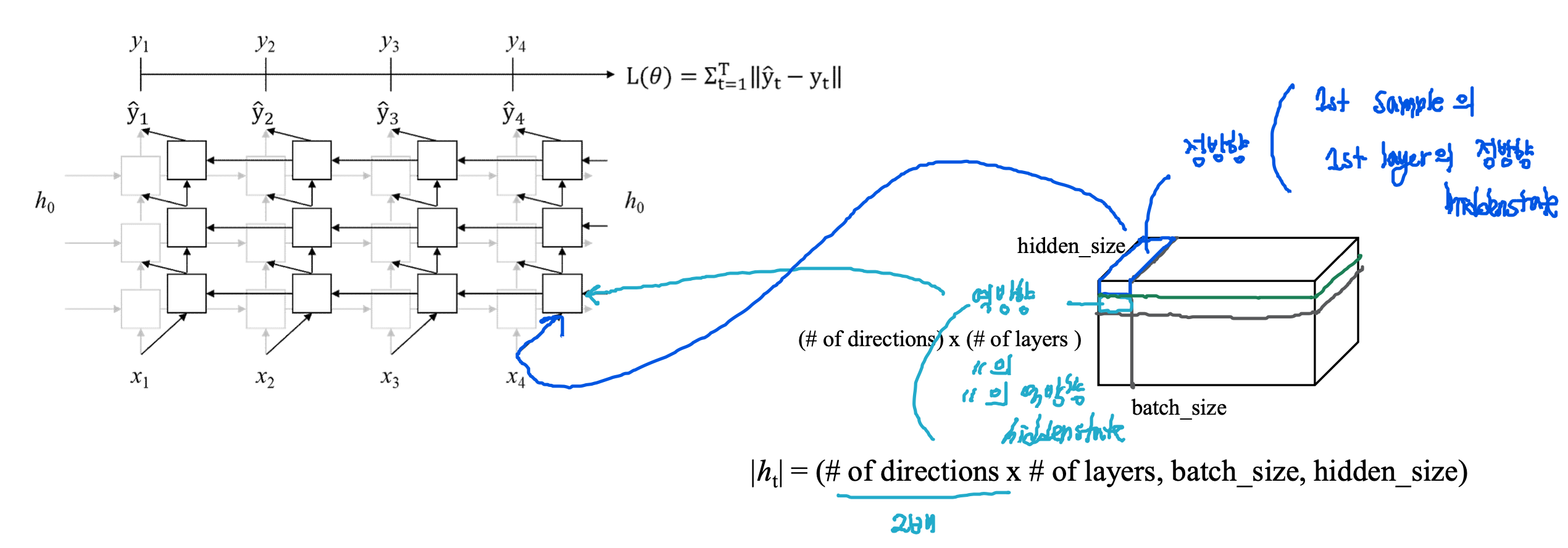
- bidirectional이므로 이 경우 은닉 상태 텐서는 (2 x number of layers, batch_size, hidden_size)
RNN 구조 요약
기본 RNN에서 은닉상태는 곧 출력
Multi-layered RNN
- 출력은 마지막 레이어의 모든 시간 스텝의 은닉 상태
- 은닉 상태는 마지막 시간 스텝의 모든 레이어의 은닉 상태
Bi-directional RNN
- 출력은 은닉 상태의 두배
- 은닉 상태는 레이어 개수의 두 배
6.1.3 RNN 활용 사례

두 가지 접근법
1) Non-autoregressive(non-generative)
- 현재 상태가 앞, 뒤 상태를 통해서 결정되는 경우
- 품사 태깅, 텍스트 분류
- 다대일, 다대다 경우에 해당
- Bidirectional RNN 사용(권장)
2) Autoregressive(generative)
- 현재 상태가 과거의 상태에 의존해서 결정되는 경우
- 자연어 생성, 기계 번역
- 일대다 경우에 해당
- Bidirectional RNN 사용 불가
RNN 활용 사례
1) 다대다
- 품사 태깅
- time step을 한번에 넣음
- bidirectional로도 구분 가능
2) 다대일

- 텍스트 분류
- 중간 결과는 필요없고, 마지막 결과만 필요
- 역방향 가능 구조
- Loss function을 최소화 하는 것이 목표
3) 일대다

- 자연어 생성
- 앞(과거)의 영향을 많이 받음
- 상대적으로 어려운 작업에 해당
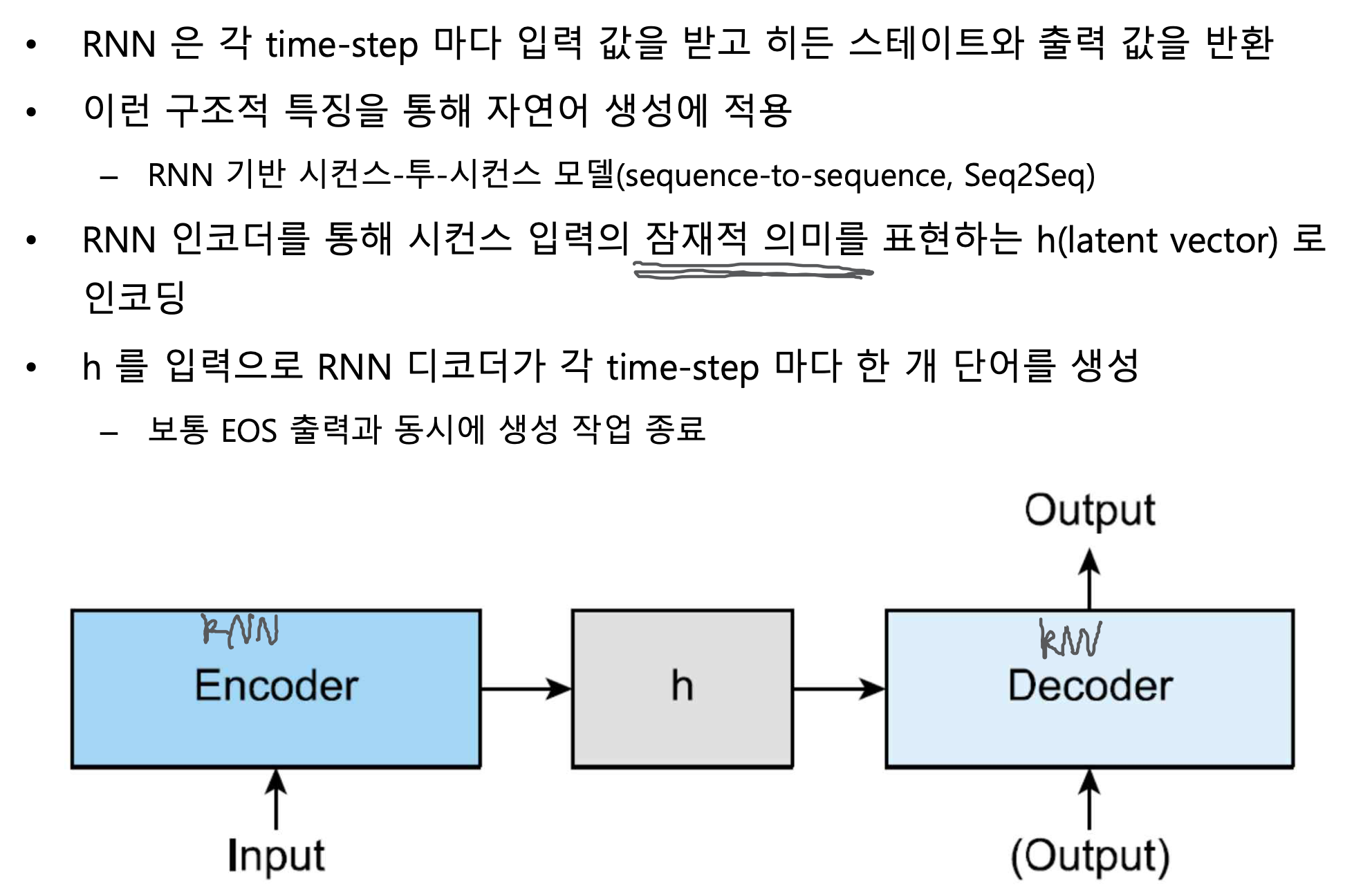
3) 일대다 : Sequence-to-sequence

- 기계번역
- encoder(다대일) : sequence를 한 점으로 압축
- decoder(일대다) : 한 점을 sequence로 압축
6.1.4 RNN 학습: Back-propagation through time(BPTT)
학습
순방향(Forward pass)
- 보통 입력값 x가 은닉층과 활성화 함수를 거쳐 h와 출력값 y를 반환
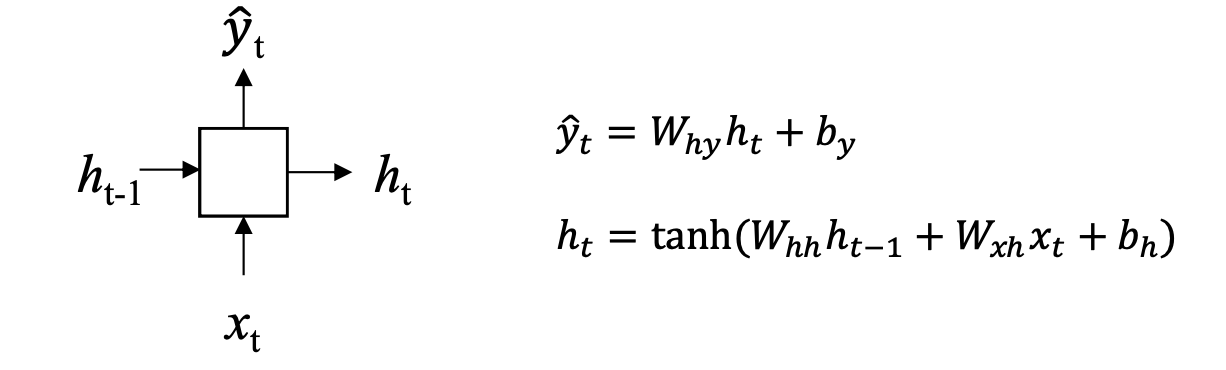
역방향(Backward pass)
- 출력부터 모든 시간 스텝에 적용되는 gradient를 모두 계산
- RNN의 구조를 펼쳐보면(unfold), RNN을 시간 스텝 수만큼 히든 레이어를 가진 deep FNN으로 볼수 있음
- 따라서 동일한 방식으로 역전파를 수행(Back-propagation througn time, BPTT)
6.2 발전된 순환 신경망 Advanced RNN
리뷰 : 심층학습 / 심층신경망 훈련 중
전제 : 기울기가 세타 업데이트에 반영이 됨
*상황 1 : 기울기가 작음
- 세타 갱신이 미약 혹은 거의 바뀌지 않음 -> 즉 학습이 되지 않음을 의미
*상황 2: 레이어가 많은 경우
- 레이어의 앞부분으로 갈수록 0~1사이 값이 곱해지면서 점점 값이 사라짐
- gradient vanishing 현상(전형적인 머신러닝의 문제점 중 하나)
gradient vanishing의 해결 방법
- He initialization
- Activation function
- Data Normalization
- Batch Normalization
- Gradient clipping(RNN에서 널리 사용)
6.2.1 그라디언트 소실 문제 (gradient vanishing problem)
RNN은 각 time-step마다 tanh, sigmoid 등 활성화 함수를 통과함
- 학습시 그라디언트 계산에서 이들을 미분하면 0~1 사이 값을 반환하는 도함수가 됨
RNN은 BPTT로 학습되므로 깊은 뉴럴 네트워크를 통과하게 됨
- 이때 그라디언트에 0~1 사이 값이 여러번 곱해지면 그라디언트가 0에 수렴하게 됨
- 즉 학습이 되지 않음
6.2.2 장단기 메모리 : Long short-term memory (LSTM)
그라디언트 소실 문제 해결을 위해 제안됨
- time step 사이에 은닉 상태와 더불어 셀 상태도 함께 전달
- 뒤의 그라디언트 소실 문제 해결법인 GRU 보다 더 널리 쓰임
- 기본 RNN에 비해 훨씬 많은 파라미터를 가짐, 즉 더 많은 학습 데이터와 학습 시간 필요
- 그라디언트 소실 문제를 해소했지만, 무작정 긴 데이터를 모두 기억 할 수 있는 건 아님
- 네트워크 용량의 한계 존재 -> 요즘 어텐션을 통해 이를 해결
Cell state란?
- 어떤 정보를 망각하고 기억할 지에 관한 판단이 반영된 정보
- 망각, 입력, 출력 게이트로 구성
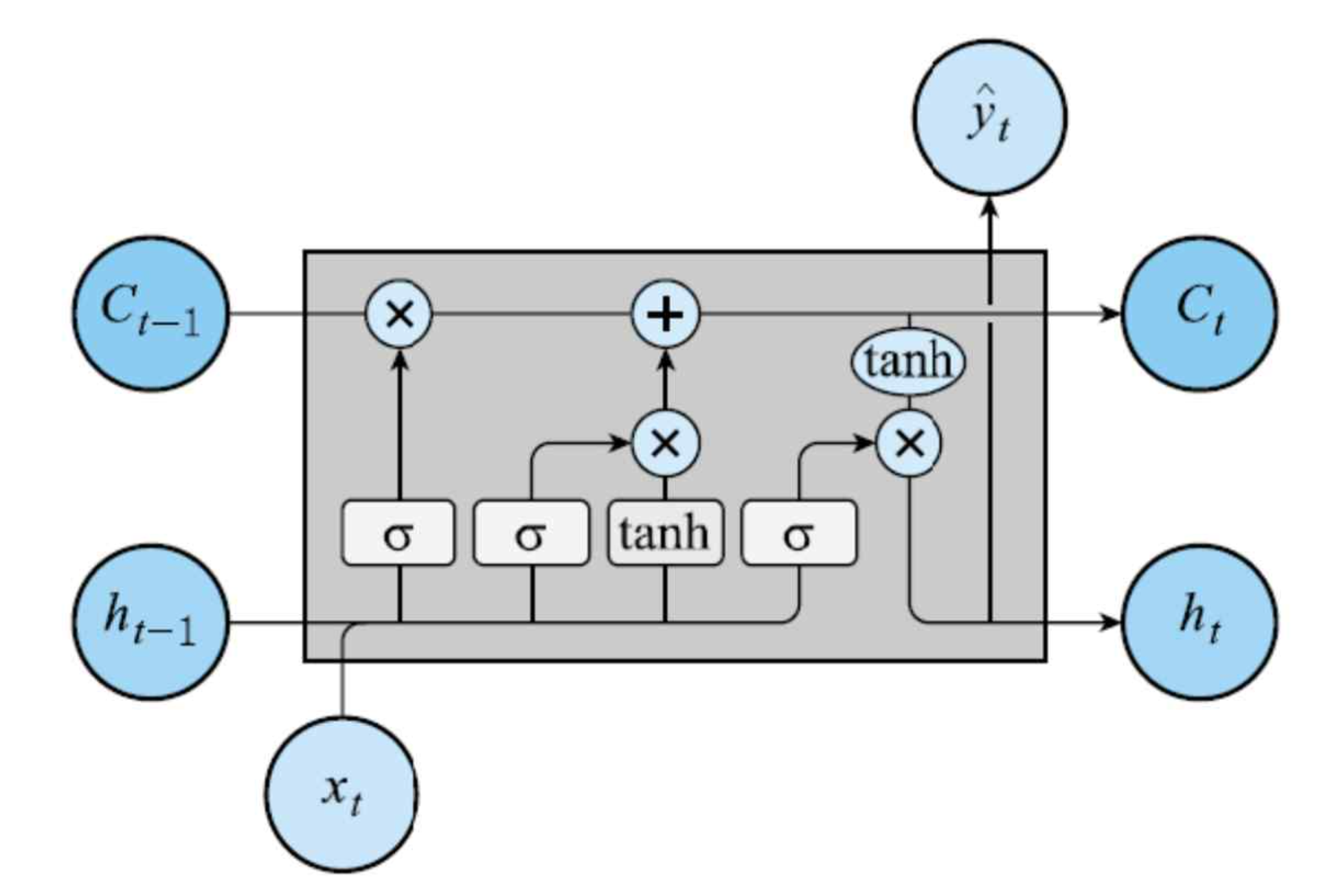
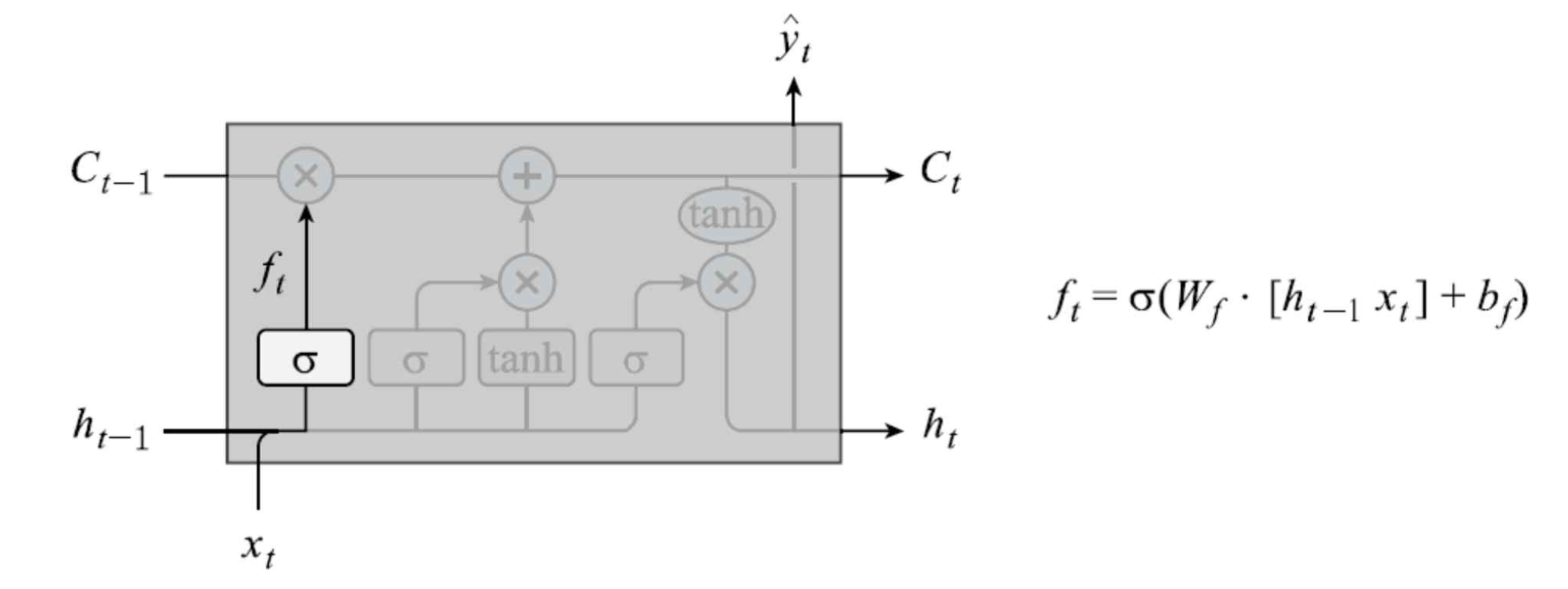
망각 게이트(Forget gate)
현재 time-step t의 입력값 x_t와 이전 히든 스테이트 h_(t-1)를 고려해, 이전 셀 스테이트를 얼마나 보존할 지 판단
입력 게이트(Input gate)
현재 time-step t의 입력값 x_t와 이전 히든 스테이트 h_(t-1)를 고려해, 셀 스테이트에 현재 상태에 대한 값을 얼마나 더할지 판단

입력 게이트와 망각 게이트로부터 얻은 값을 통해 셀 스테이트 업데이트

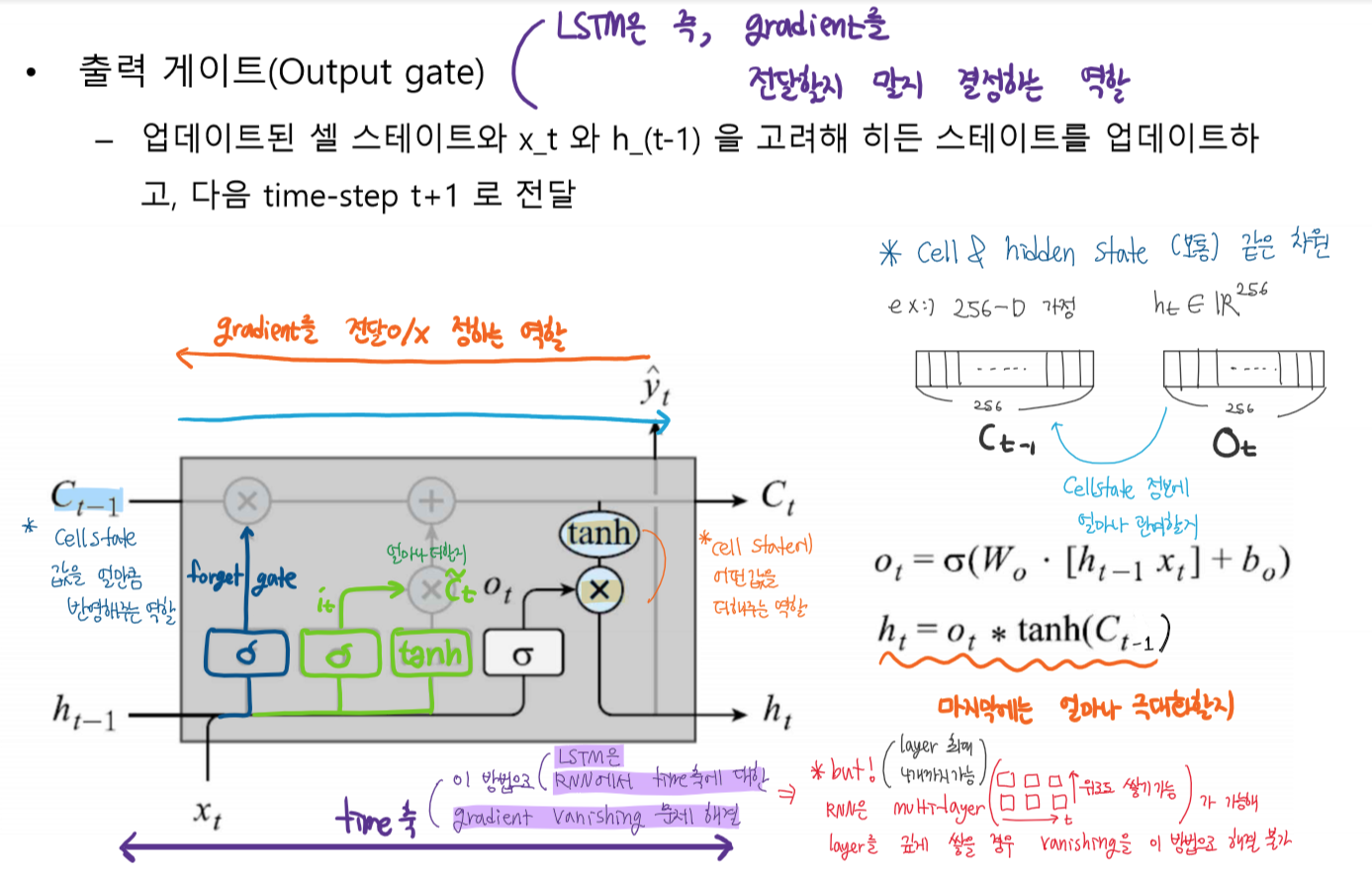
출력 게이트(Output gate)
업데이트 된 셀 스테이트와 x_t와 h_(t-1)를 고려해 히든 스테이트를 업데이트 하고 다음 time-step t+1 로 전달
6.2.3 게이트 순환 유닛 : Gated recurrent unit (GRU)
LSTM 보다 간소화되었으며, 별도의 셀 스테이트 없이 두 개의 게이트를 사용하여 그라디언트 소실 문제를 해결하고자 함
리셋 게이트와 업데이트 게이트로 구성됨

리셋 게이트(Reset gate)

- 이전 히든 스테이트 h_(t-1)과 현재 입력 값 x_t를 고려해, 현재 입력 값을 히든 스테이트 h_t에 얼마나 반영할 지 판단
업데이트 게이트(Update gate)
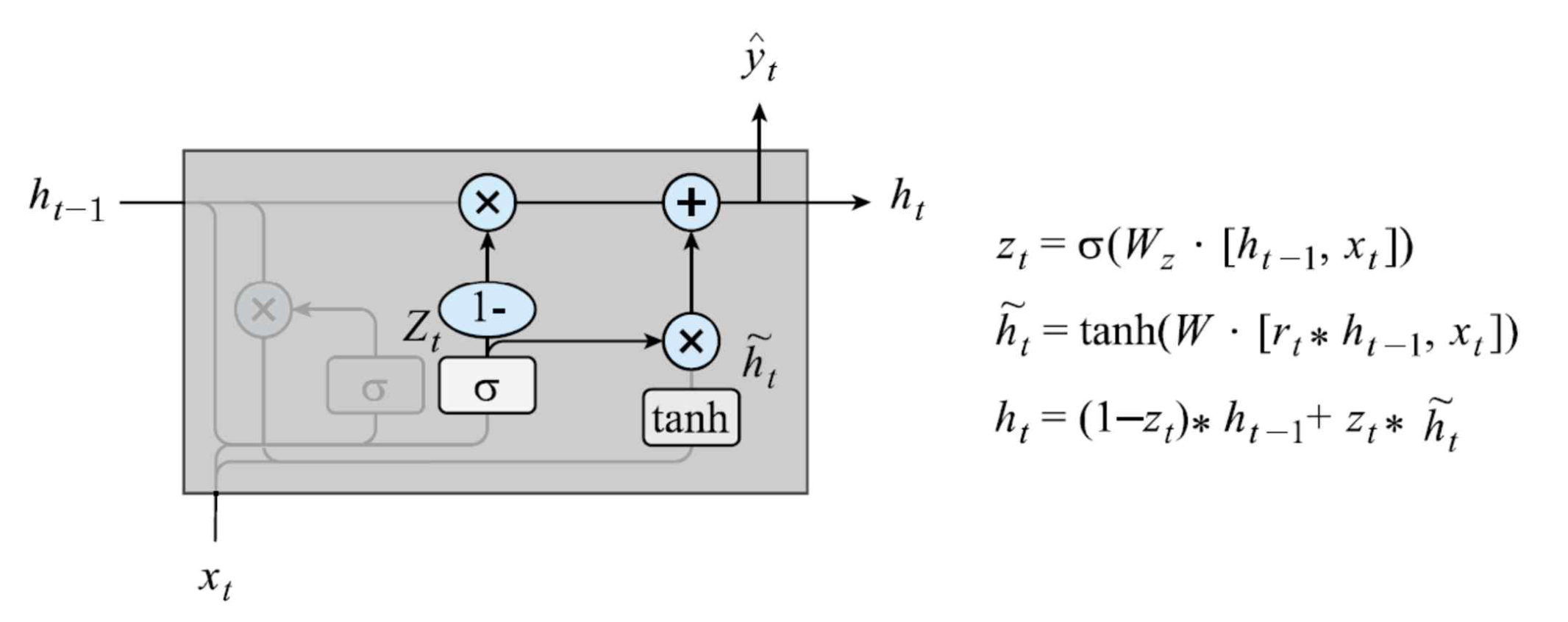
- 히든 스테이트 h_(t-1)과 현재 입력 값 x_t로부터 z_t값을 생성하고 z_t를 기준으로 리셋 게이트로부터 반환된 값과 이전 히든 스테이트 중 어디에 얼만큼 가중치를 둘 지 판단
6.2.4 그라디언트 클리핑 (gradient clipping)
Time-step이 길어질수록 BPTT 알고리즘에서 gradient의 덧셈이 많아짐
- 긴 시퀀스인 경우 더 심화되는 증상
- 즉 gradient를 작게 만드는게 해결책
파라미터 업데이트
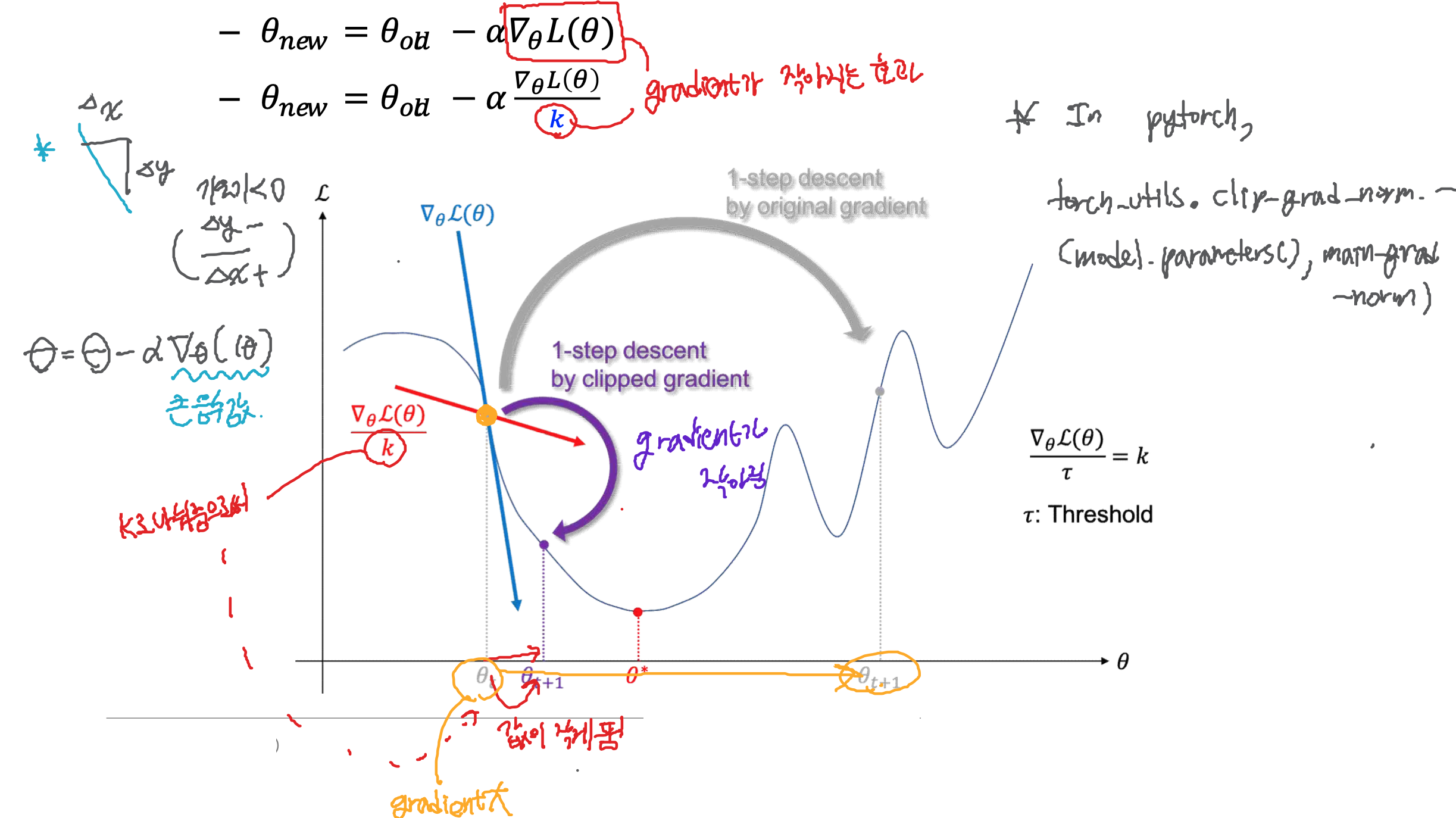
- 새로운 세타를 갱신해주는 방법은 old세타에 loss function*gradient*running mate 알파를 빼주는 것
- k를 나눠줌으로써 gradient가 작아지는 효과가 있음
- Adam optimizer를 사용할 경우 크게 쓰이지 않음
6.3 RNN 기반 자연어 생성 (PASS)