04 텍스트의 전처리

목차
4. 텍스트의 전처리
4.0 NLP 프로젝트 워크플로우
4.1 비정형 데이터내의 오류
4.2 텍스트 문서의 변환
4.3 띄어쓰기 교정 방법
4.4 철자 및 맞춤법 교정 방법
4.0 NLP 프로젝트 워크플로우
4.1 비정형 데이터내의 오류
비정형 데이터란?
- 일정한 규격이나 형태를 지닌 숫자 데이터와 달리 그림이나 영상, 문서처럼 형태와 구조가 다른 구조화되지 않은 데이터
비정형 데이터의 정형화
- 분석을 위해서 정형화가 요구됨. 해당 과정을 전처리라고 함
- 세상에 존재하는 대부분의 가공되지 않은 데이터는 비정형 데이터의 형식이므로 해당 과정은 필수적
4.2 텍스트 문서의 변환
전처리 단계
1. 파일로부터 텍스트 추출
2. 문서파일 -> 문서
- 목표 어휘언어의 문자만 남김
- 특수 문자 및 불필요한 문자 제거 필요
3. 각 단어들을 모두 배열 형식으로 구분 지음
- 이후 단어를 구분 짓는 잣대를 통일, 차후 텍스트 처리 시 일관성 부족으로 생길 오류나 불상사를 방지
4. 인터렉티브한 노이즈 제거 과정
- 규칙에 의해 노이즈를 제거하는 것은 노이즈 전부를 제거하기 어려움
- 반복적인 규칙생성 및 적용 과정이 필요
5. 텍스트 에디터 이용 방법(for 정규식)
- subime text3
- EmEditor
4.3 띄어쓰기 교정 방법
띄어쓰기
- 한국어는 크게 의미분절, 가독성, 의미혼용 방지의 용도
4.3.1 규칙 기반
- 형태소 분석기(띄어쓰기 전처리를 하기 위함)를 사용하는 규칙기반의 분석적인 방법
- 규칙 : 주로 어휘지식, 규칙, 오류 유형 등의 휴리스틱 규칙(사람들이 경험을 통해 만든 규칙들)을 이용
- 장점 : 매우 높은 정확도
- 단점 : 손수 제작해야 하므로 시간적, 인적 비용이 크며 시스템 유지 및 보수가 어려움
어절 블록 양방향 알고리즘
- 조사나 어미로 쓰이는 음절이 극히 제한적이라는 특성 이용
- 띄어쓰기가 되지 않은 입력 문장에서 어절 경계에 해당하는 부분을 찾음
- 의미적으로 중의성을 띄는 구간이나 오타에는 성능이 크게 약해짐
4.3.2 통계 확률 기반
- 언어 모델링 방법을 사용해 학습 코퍼스내에서 수정 방향이 옳을 확률이 높은 후보들을 차례로 나열
- 가장 확률이 높은 후보로 교정 수행
- 장점 : 구현 용이
- 단점: 학습 코퍼스의 영향을 크게 받아 오류율이 높음, 대량의 학습 데이터를 요구
4.4 철자 및 맞춤법 교정 방법
철자 교정
- 정확한 의미 전송 및 정보 교환에 필요
- 이를 위해 시행하는게 맞춤법 검사
맞춤법 및 철자 교정기의 두 가지 수행 역할
- 텍스트 내 오류 감지
- 오류의 수정
오타로 인해 발생할 수 있는 오류
- 삽입 : 추가적으로 문자가 입력된 경우
- 생략 : 철자가 빠진 경우
- 대체 : 본래 넣어야 할 문자 대신 타 문자가 대입된 경우
- 순열 : 순서 뒤바뀜
4.4.1 규칙 기반
언어 현상의 규칙성을 추가로 응용하는 방식
- 어절은 어절보다 작은 단위인 형태소들이 일정한 규칙에 따라 결합하여 이루어짐
- 어절을 형태소들로 분절하는 형태소 분석기를 사용한 방식이 존재
- 띄어쓰기 교정기의 규칙기반 방법 장단점과 흡사함
맞춤법 교정 과정

4.4.2 통계, 확률 기반
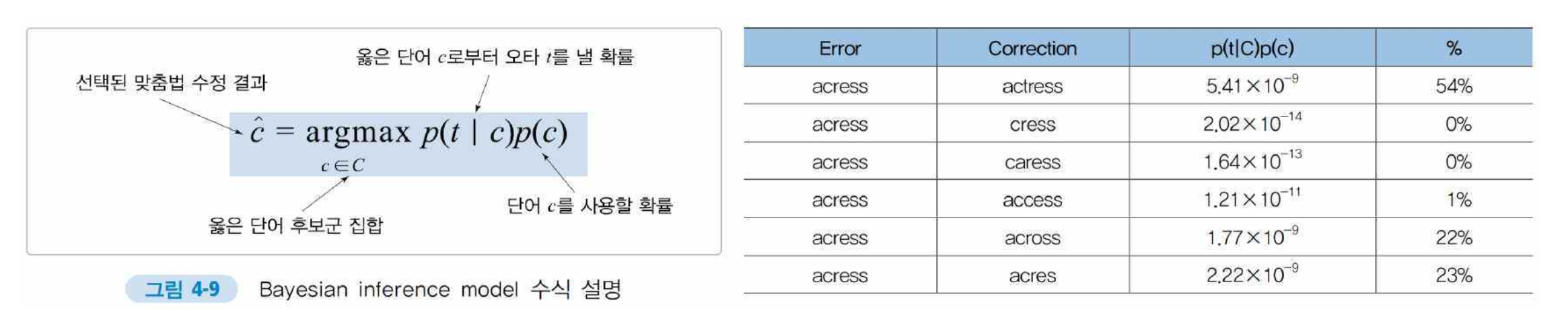
Bayesian inference model
- 올바른 교정결과를 도출하기 위해 주어진 단어로부터 오타가 일어날 확률을 확률적으로 계산하는 방법