End-to-End Memory Networks, 엔드-투-엔드 메모리 네트워크
End-to-End Memory Networks
2015년 NIPS에 FaceBook AI Research가 발표한 논문으로 당시 자연어처리 분야에서 가장 좋은 성능을 보여주었던 모델 중 하나입니다. 기존의 일반적인 신경망 모델과 다르게 메모리(Memory)라는 구조를 사용한다는 점이 가장 큰 특징입니다.
Model Architecture(1): Single Layer
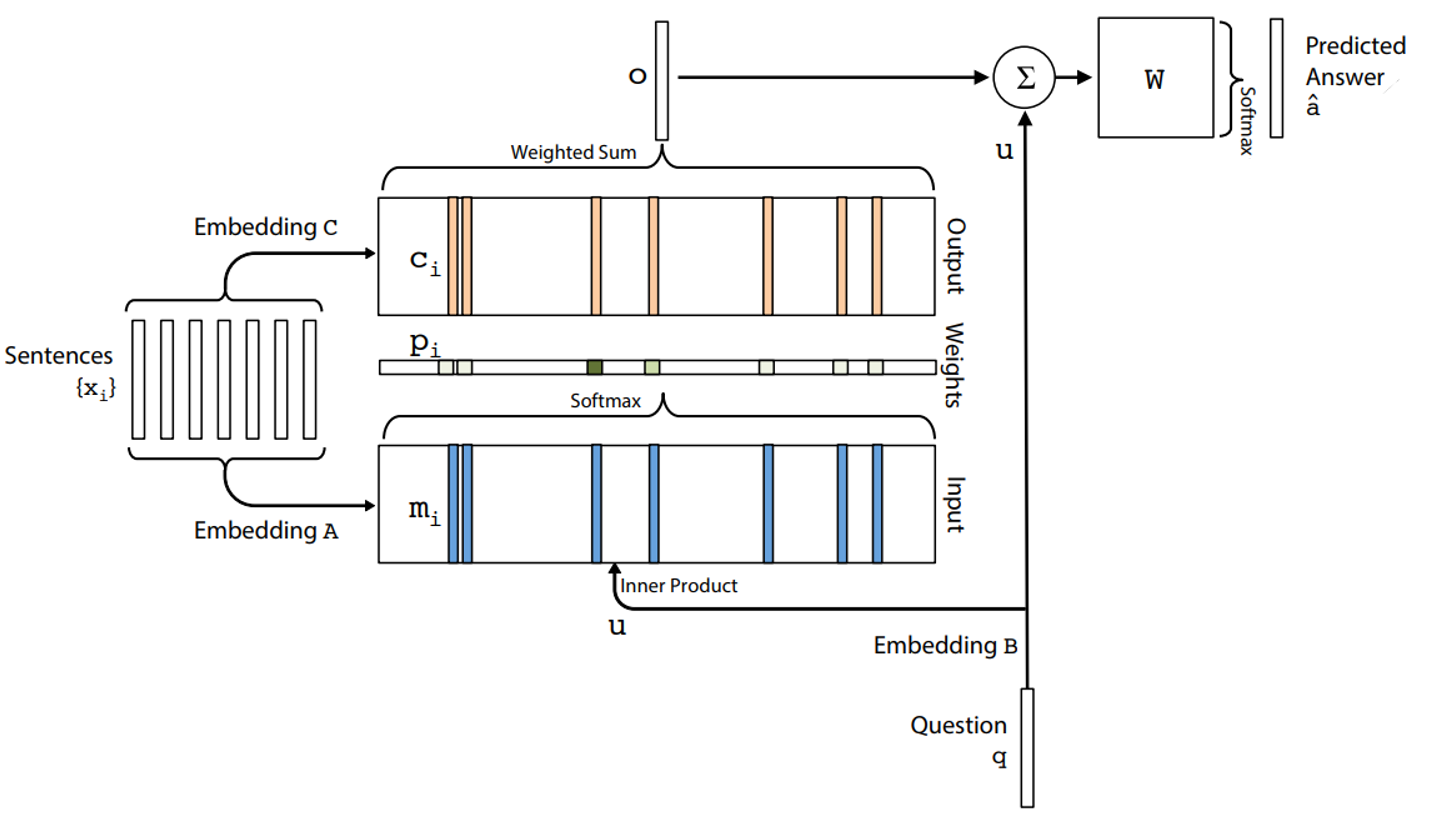
이해를 돕기 위해 먼저 본 논문에서 제안하는 모델의 싱글 레이어 구조를 살펴보도록 하겠습니다. 모델의 입력값으로는 Context 문장, Question 문장이 들어가고 학습시 업데이트 되는 파라미터는 Fig1.의 Embedding $A,B,C$와 Weight Vector $W$입니다. 모델의 학습 과정은 크게 다음과 같이 세 단계로 이루어집니다.
Step1
모델의 입력값으로 Context 문장들인 Sentences {$x_i$}와 Question $q$가 들어갑니다. 이는 아래와 같이 구성될 수 있습니다.

해당 문장들을 BoW(Bag-of-Words) 기법을 이용하여 각각의 단어들을 벡터 형태로 변환합니다. Bow에 대한 자세한 설명은 [NLP] 단어 표현 방법: Bag-of-Word Model(BoW) 게시글을 참고하면 좋습니다.

이후, 벡터화된 Context 문장들의 각각의 단어에 Embedding matrix $A$를 곱하여 Embedding vectors로 변환하고 이를 모두 더하여 메모리 벡터 $m_i$를 구합니다. 이는 Fig1의 전체 구조에서 아래의 Fig2.1에 노란색 부분에 해당합니다.

이는 아래의 수식처럼 표현할 수 있고, 실제 모델 동작 시 $m_i$들 중 일부를 사용하게 됩니다.
$$m_i=\sum_{j}Ax_{ij}$$
Question $q$도 같은 방식으로 Embedding matrix $B$를 곱하여 각각의 단어를 Embedding vertor $u$로 변환합니다.
추가로 Context문장들의 각각의 단어에 다시 Embedding matrix $C$ 곱하여 각각의 단어를 Embedding vectors $c_i$로 변환합니다.

Step2
Context 문장들 중에서 어떤 부분을 중요하게 볼 지를 나타내는 Attention 정도를 질문으로부터 추출한 Embedding vector $u$와 Context 문장으로부터 만든 메모리 $m_i$에 소프트맥스 함수를 적용해서 계산합니다.
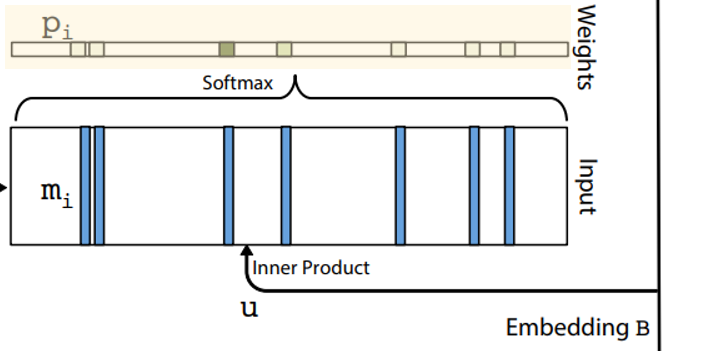
이는 아래의 수식처럼 표현할 수 있습니다.
$$p_i = Softmax(u^Tm_i)$$
Step3
Attention정도를 나타내는 나타내는 $p_i$와 Context문장으로부터 만든 Embedding Vector $c_i$를 모두 더해서 output $o$를 구합니다.
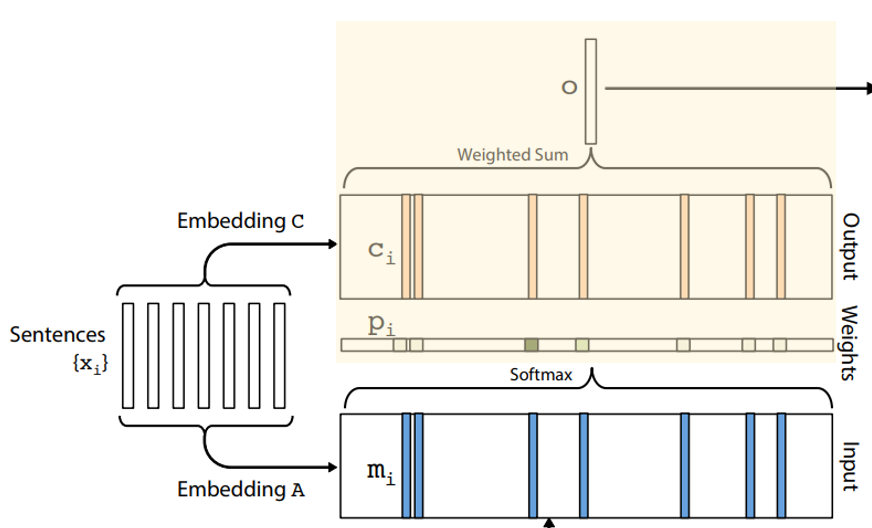
이는 아래의 수식처럼 표현할 수 있습니다.
$$o = \sum_{i}p_ic_i$$
마지막으로 output $o$와 Question $q$로부터 추출한 Embedding vector $u$에 가중치값 $W$를 곱하여 더한 뒤 소프트맥수 함수를 적용하여 답 $\hat{a}$를 추론합니다.
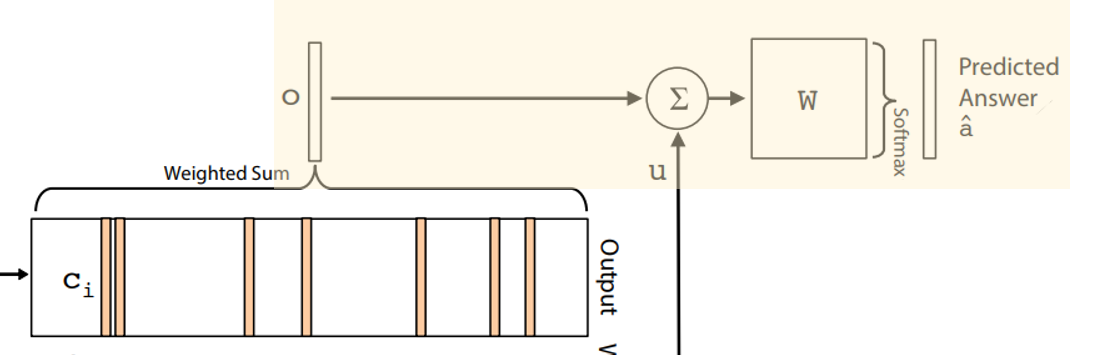
이는 아래의 수식처럼 표현 할 수 있습니다. 따라서 모델에 의해 최종 추론된 답, 즉 모델의 출력값이 됩니다.
$$\hat{a} = Softmax(W(o+u))$$
Model Architecture(2): Multi-Layer
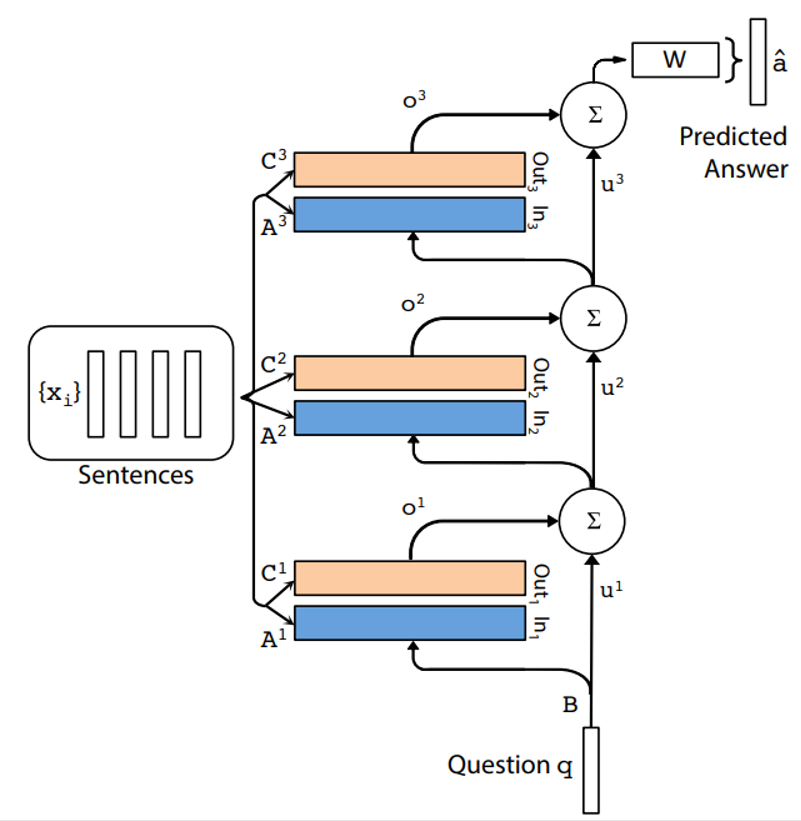
위에서 설명드린 싱글레이어 구조를 멀티 레이어 구조로 구성하면 Fig.5와 같습니다. 이는 싱글레이어 구조를 쌓은 형태로 다음 방법에 따라 구성됩니다
a. $k+1$번 째 Layer 입력은 $k$번 째 Layer의 입력값 $u^k$와 출력값 $o^k$의 합으로 구성됩니다.
$$u^{k+1}=u^k+o^k$$
b. 각 레이어는 자신들만의 embedding matrix $A^k, C^k$를 가지고, input {$x_i$}를 임베딩 하는데 사용합니다
c. 맨 위의 네트워크에는 가중치 $W$의 입력값으로 맨 위의 메모리 레이어의 출력값과 입력값의 합이 들어가게 됩니다.