딥러닝 모델에서의 분산학습(Distributed Training)
해당 게시글은 자연어처리 리뷰 모임인 집현전 팀의 고현웅님의 [Large-scal LM에 대한 얕고 넓은 지식들(part1)] 부분의 Parallelism: Theory and Practice 강의 영상을 기반으로 작성되었습니다.
Intro.
딥러닝 모델에서는 학습 시 대용량의 모델 크기와 학습 데이터 때문에 여러 GPU에 나누어 연산하는 분산학습(Distributed Training)이 이루어져야 GPU를 최대한 활용하여 효율적으로 학습할 수 있습니다. 이러한 딥러닝 분산학습에는 학습 데이터를 여러 GPU에 나누어 학습하는 데이터 병렬화(Data Parallelism)와 모델을 여러 GPU에 나누는 모델 병렬화(Model Parallelism)와 입력 미니배치를 여러 GPU에 나누어 실행하는 파이프라인 병렬화(Pipeline Parallelism)로 크게 세 가지 기법으로 나눌 수 있습니다.

데이터 병렬화(Data Parallelism)
데이터가 많을 때, 데이터를 병렬처리하여 학습속도를 끌어올리는 작업입니다. 모든 디바이스에 모델을 복사하고 서로 다른 데이터를 각 디바이스에 입력합니다. 이 경우 배치 사이즈를 디바이스 수의 배수만큼 더 많이 입력할 수 있으나 이러한 데이터 병렬화의 경우 모델 하나가 디바이스 하나에 완전히 올라갈 때만 가능하다는 단점이 있습니다.

모델 병렬화(Model Parallelism)
모델이 너무 커서 하나의 디바이스에 담을 수 없을 때 파라미터를 쪼개서 올리는 방법으로, 각 디바이스에 모델의 파라미터 일부분들이 담겨있습니다. 이를 이용하면 큰 모델도 작은 디바이스 여러 개를 이용하여 올릴 수 있습니다.
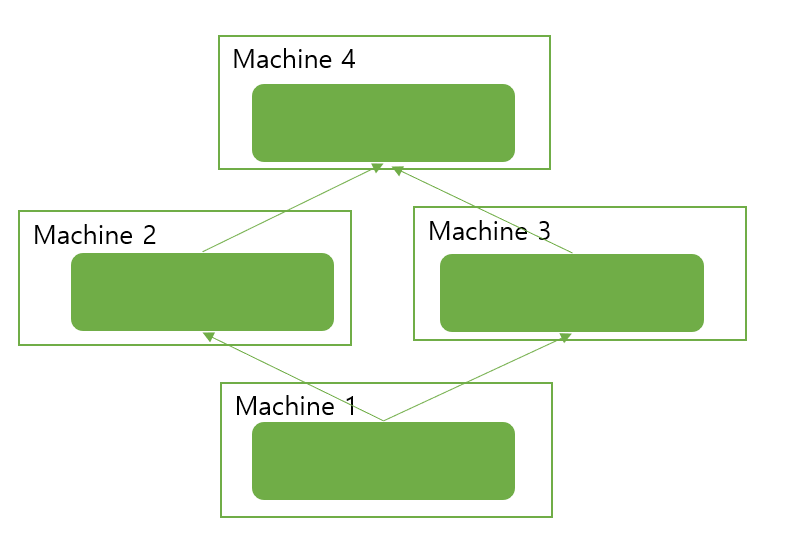
파이프 라인 병렬화(Pipeline Parallelism)

레이어 단위로 모델 병렬화를 수행할 경우 반드시 레이어 순으로 실행해야 합니다. 위의 그림에서 Fn은 n번째 forward computation function을 나타내며 Bn은 n번째 back-propagation function을 나타냅니다. 그림은 4개의 다른 GPU(세로축)에 4개의 레이어가 배치된 모델을 나타냅니다. 가로축은 한 번에 하나의 GPU만 활성화되는 것을 나타냅니다.
따라서 레이어 단위의 모델 병렬화를 수행할 경우 연산 과정의 순서가 생길 수 밖에 없습니다. 즉, 훈련 프로세스에서 GPU 사용률이 저하됩니다. 바로 이 연산과정을 효율적으로 하기 위해 병렬적으로 파이프라이닝(Pipelining)하는 것이 파이프라인 병렬화입니다.
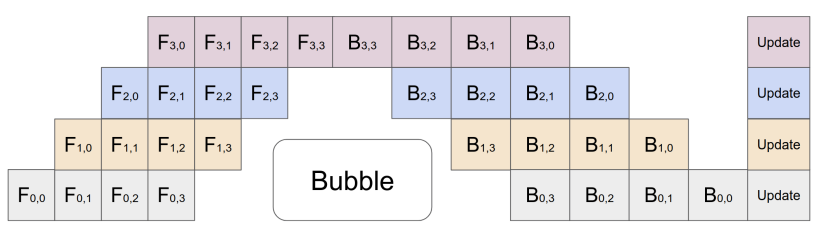
위 그림에서는 이 문제를 완화하기 위해 입력 미니 배치를 여러 마이크로 배치로 분할하고 이를 여러 GPU에서 실행하는 파이프 라인을 나타냅니다. 그림은 4개의 다른 GPU(세로출)에 4개의 레이어가 배치 된 모델을 나타냅니다. 수평 축은 기본 모델 병렬화보다 GPU가 훨씬 더 효율적으로 활용되고 있음을 보입니다. 하지만 여전히 특정 GPU가 사용되지 않는 거품(Bubble)이 존재합니다.